
Mastering Databases: From Optimizing Queries to Distributed Systems
Databases are at the core of modern applications, from e-commerce to social platforms, powering billions of transactions every second. In this blog, we’ll explore key concepts that every software engineer should understand—ranging from JOINs, partitioning, sharding, and query optimization to security best practices. This post serves as a comprehensive guide to help you understand, design, and maintain efficient databases.
1. SQL JOINs: Types and When to Use Them
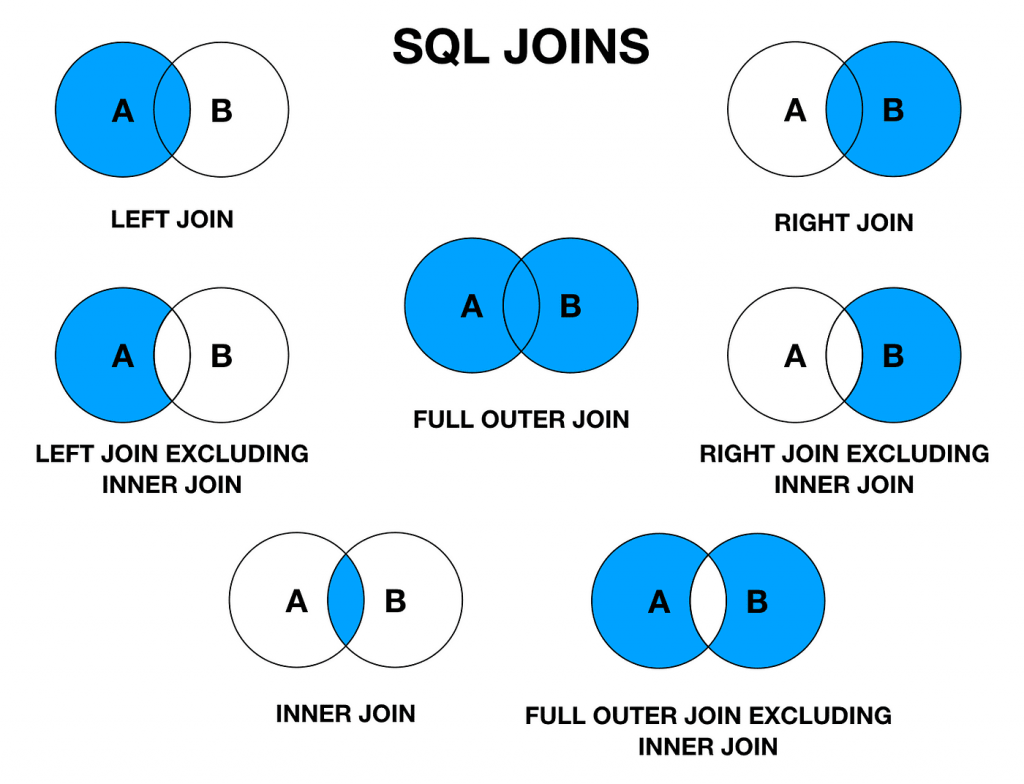
SQL JOINs allow us to retrieve data from multiple related tables in relational databases. Understanding the differences between JOIN types ensures you can query efficiently.
| JOIN Type | Description | Use Case |
|---|---|---|
| INNER JOIN | Returns rows with matching values in both tables | Default join when matching relationships are needed |
| LEFT JOIN | Returns all rows from the left table, even if no match | Use when you need all rows from the left, with or without matches |
| RIGHT JOIN | Returns all rows from the right table | Rarely used—opposite of LEFT JOIN |
| FULL OUTER JOIN | Returns all rows when there’s a match in either table | Use when all data needs to be fetched regardless of matching |
| CROSS JOIN | Returns the Cartesian product of both tables | Be cautious—creates a large result set |
Performance Tip: Avoid unnecessary JOINs and filter data early to minimize the data processed. Use indexes on frequently joined columns to improve performance.
2. Query Optimization Techniques

Optimizing queries ensures faster responses and reduced resource consumption. Below are techniques to keep in mind:
- Indexes: Create indexes on frequently queried columns to improve retrieval times.
- Use LIMIT & OFFSET: Limit rows fetched to prevent fetching unnecessary data.
- Avoid SELECT: Select only required columns to reduce I/O overhead.
- Partitioning: Divide large tables into smaller, more manageable parts.
- Analyze Query Execution Plans: Use EXPLAIN to understand query execution paths.
- Caching: Use Redis or Memcached to cache frequently accessed data.
3. Handling Transactions: Error Handling & Security Risks
Transactions ensure data consistency by grouping multiple operations into a single atomic unit. However, they also need careful error handling.

• Rollback on Error: Use TRY-CATCH blocks to handle failures gracefully.
BEGIN TRANSACTION;
BEGIN TRY
INSERT INTO Orders VALUES (1, 'Product A', 100);
INSERT INTO Payments VALUES (1, 'Card', 100);
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
ROLLBACK TRANSACTION;
PRINT ERROR_MESSAGE();
END CATCH;• Deadlocks: Occur when multiple transactions block each other. Use timeouts or detect deadlocks using the database’s deadlock detection mechanisms.
• SQL Injection Attacks: Always use parameterized queries to prevent injection attacks.
4. Partitioning vs. Sharding: Scaling Databases
When scaling databases, engineers often need to decide between partitioning and sharding. Both techniques divide data, but they differ in scope and purpose.
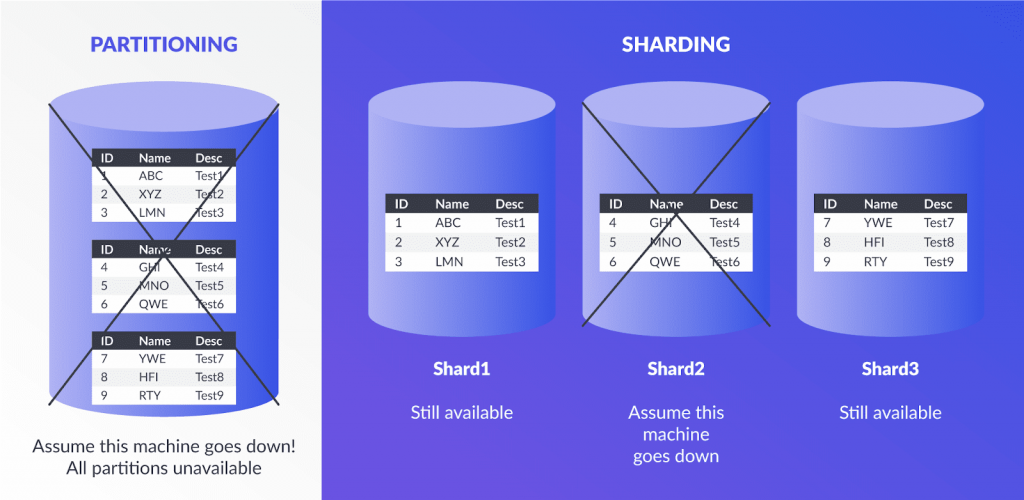
| Aspect | Partitioning | Sharding |
|---|---|---|
| Scope | Within one database | Across multiple databases or servers |
| Goal | Improve query performance | Horizontal scalability |
| Types | Range, List, Hash | Horizontal, Vertical |
| Example | Splitting sales by month | Each shard contains users by region |
Use Cases:
• Partitioning: Ideal for a single large table that needs faster access.
• Sharding: Use when the application needs to distribute huge datasets across multiple servers.
5. Security Considerations: Preventing Token Abuse in Databases
Security is paramount in any system. A critical issue arises when an access token and refresh token fall into the wrong hands. To handle such cases:
- Rotate Tokens: Issue new tokens periodically to limit exposure.
- Blacklist Compromised Tokens: Maintain a blacklist of compromised tokens to deny access.
- Store Refresh Tokens Securely: Encrypt refresh tokens or use HttpOnly cookies to prevent client-side access.
- Detect Suspicious Activity: Monitor token usage and trigger alerts on anomalies, such as tokens being used from different locations.
6. Migration from MongoDB to PostgreSQL: Best Practices

Migrating 100 million records from MongoDB to PostgreSQL requires a well-planned strategy. Follow these steps:
- Schema Design: Convert MongoDB’s document-based structure to a relational schema.
- ETL Process: Extract, transform, and load data in batches.
- Batch Migration: Migrate data in smaller parts to reduce pressure on the system.
- Verification: Compare data between MongoDB and PostgreSQL after each batch to ensure consistency.
7. Handling Data Loss and Recovery
Preventing and recovering from data loss requires multiple layers of backup and replication strategies:
- Backups: Regularly back up data and store in multiple locations.
- Replication: Use database replication to maintain copies of data across servers.
- Snapshots: Take snapshots of the database at critical points.
- Logging: Maintain transaction logs to recover the latest data state.
Conclusion
Managing databases effectively requires a deep understanding of query optimization, partitioning vs. sharding, event loops, and distributed systems. Whether you’re building scalable applications, migrating data between systems, or preventing security breaches, mastering these concepts will set you apart as a seasoned software engineer.
The knowledge covered in this blog lays a solid foundation for managing modern databases efficiently—empowering you to handle data at scale, ensure security, and optimize performance across distributed systems.



2 comments