
Semantic Caching trong Hệ thống LLM: Hướng Dẫn cho Người Mới
Vì Sao LLM API Của Bạn Đang “Đốt Tiền” Mỗi Ngày?
Hãy tưởng tượng bạn đang vận hành một chatbot hỗ trợ khách hàng được xây dựng trên GPT-4. Mỗi ngày, hàng trăm người dùng gõ vào những câu hỏi như “Làm sao để đổi mật khẩu?”, “Cách đổi password?”, “Tôi muốn thay đổi mật khẩu tài khoản”, “Reset password như thế nào?”… Về mặt kỹ thuật, đây là bốn câu hỏi khác nhau. Nhưng về mặt ý nghĩa, chúng hoàn toàn giống nhau.
Nếu hệ thống của bạn gọi LLM API cho mỗi request, bạn đang trả tiền bốn lần cho cùng một câu trả lời. Nhân con số đó lên với hàng nghìn người dùng mỗi ngày, và bạn sẽ thấy chi phí API có thể leo thang nhanh đến mức đáng sợ — chưa kể mỗi lần gọi LLM còn mất từ 1 đến 10 giây để phản hồi.
Đây chính là vấn đề mà semantic caching được sinh ra để giải quyết. Không giống như traditional caching chỉ khớp chính xác từng ký tự, semantic caching hiểu được ý nghĩa đằng sau câu hỏi — và trả về kết quả đã lưu sẵn khi một câu hỏi tương tự xuất hiện, dù cách diễn đạt có khác nhau đến đâu.
Bài viết này sẽ giải thích semantic caching từ đầu: cách hoạt động, tại sao nó quan trọng, công cụ nào nên dùng, và làm thế nào để bắt đầu — ngay cả khi bạn chưa có kinh nghiệm sâu về ML infrastructure.
Semantic Caching Là Gì? (Và Khác Gì So Với Traditional Caching?)
Nói đơn giản: semantic caching là kỹ thuật lưu trữ phản hồi của LLM và tái sử dụng chúng khi có một câu hỏi có ý nghĩa tương tự được gửi đến — dù không cần giống từng chữ.
Hãy so sánh với traditional caching qua một ví dụ cụ thể:
- Traditional cache: “What is the capital of France?” và “What’s France’s capital?” → hai cache miss, vì chuỗi ký tự khác nhau.
- Semantic cache: Hai câu trên có cùng nghĩa → một cache hit, trả về cùng một câu trả lời đã lưu.
Dưới đây là bảng so sánh tổng quan:
Traditional Caching vs. Semantic Caching
Match type: Exact string match → Meaning/intent match
Flexibility: Thấp → Cao
Storage: Key-value (string → response) → Vector + key-value
Lookup speed: O(1) hash lookup → Vector similarity search
Miss rate: Cao (bất kỳ thay đổi nào = miss) → Thấp hơn (câu hỏi tương tự = hit)
Infrastructure: Redis, Memcached → Vector DB + cache store
Rõ ràng, semantic caching đòi hỏi infrastructure phức tạp hơn — nhưng đổi lại, nó mang lại lợi ích vượt trội cho các ứng dụng LLM có lượng query lặp lại cao.
Semantic Caching Hoạt Động Như Thế Nào Bên Trong?
Quy trình hoạt động của semantic caching có thể chia thành các bước sau:
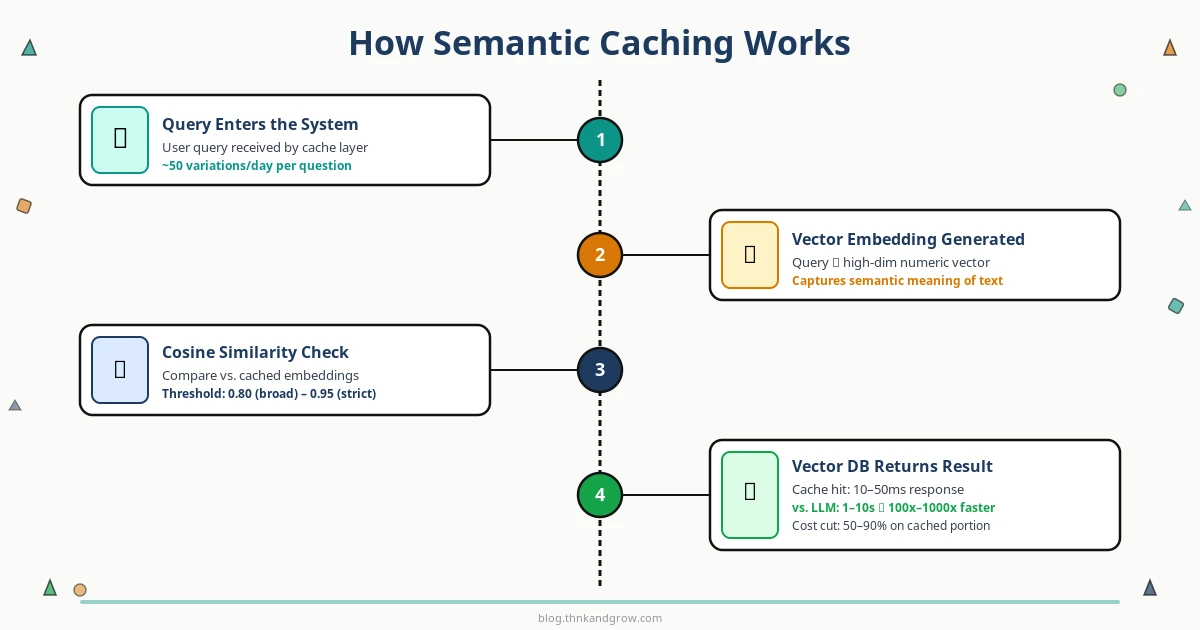
- Query đến: Người dùng gửi một câu hỏi.
- Embedding: Câu hỏi được chuyển đổi thành một vector số học (vector embedding) bằng một embedding model.
- Similarity search: Vector mới được so sánh với các vector đã lưu trong vector database bằng cosine similarity hoặc các distance metric khác.
- Cache hit hay miss: Nếu độ tương đồng vượt ngưỡng (similarity threshold) đã cấu hình → trả về cached response. Nếu không → gọi LLM API.
- Lưu và trả về: Kết quả từ LLM được lưu vào cache (cùng với embedding của query) và trả về cho người dùng.
Vector Embeddings Là Gì?
Nếu bạn chưa quen với khái niệm này, hãy nghĩ đơn giản như sau: vector embedding là cách chuyển đổi một đoạn văn bản thành một danh sách các con số — ví dụ [0.12, -0.45, 0.87, ...] — sao cho các văn bản có nghĩa tương tự sẽ có các vector “gần nhau” trong không gian toán học.
Ví dụ: “Cách đổi mật khẩu” và “Làm sao reset password” sẽ có vector rất gần nhau, trong khi “Thời tiết hôm nay thế nào?” sẽ có vector ở xa hơn nhiều.
Cosine Similarity và Similarity Threshold
Cosine similarity đo góc giữa hai vector: giá trị từ 0 (hoàn toàn khác nhau) đến 1 (giống hệt nhau). Khi bạn cấu hình semantic cache, bạn sẽ đặt một similarity threshold — ví dụ 0.85. Nếu hai query có cosine similarity ≥ 0.85, hệ thống coi chúng là “đủ giống nhau” và trả về cached response.
Đây là thông số quan trọng nhất cần tinh chỉnh, và chúng ta sẽ bàn kỹ hơn ở phần Best Practices.
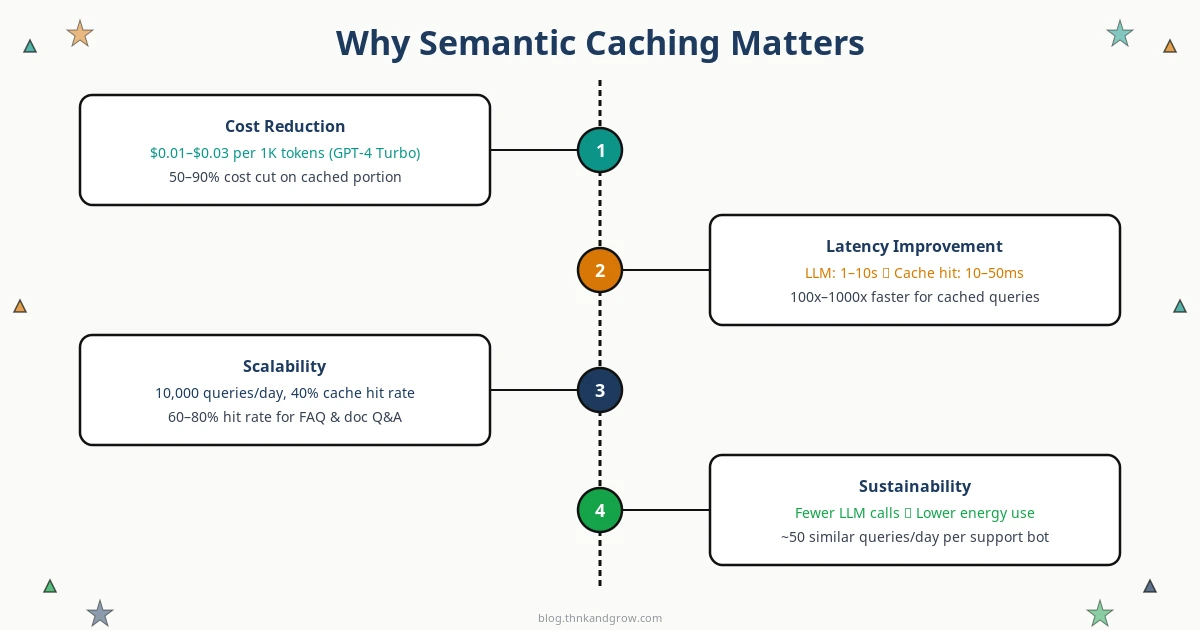
Tại Sao Semantic Caching Quan Trọng: Chi Phí, Tốc Độ, và Khả Năng Mở Rộng
Giảm Chi Phí API Đáng Kể
GPT-4 Turbo có giá khoảng $0.01–$0.03 mỗi 1.000 token. Với một ứng dụng FAQ bot nhận 10.000 query mỗi ngày, trong đó 60% là các câu hỏi tương tự nhau, bạn có thể tiết kiệm hàng trăm đô la mỗi tháng chỉ bằng cách không gọi API cho những câu hỏi đã có câu trả lời trong cache.
Cải Thiện Latency Đáng Kể
LLM inference thường mất 1–10 giây hoặc hơn tùy thuộc vào độ dài output. Một cache hit chỉ mất 10–50ms — nhanh hơn gần 100 lần. Với người dùng cuối, đây là sự khác biệt giữa trải nghiệm “mượt mà” và “chờ đợi mỏi mòn”.
Khả Năng Mở Rộng
Khi ứng dụng của bạn scale lên, chi phí API tăng tuyến tính nếu không có caching. Semantic caching cho phép bạn phục vụ nhiều người dùng đồng thời hơn mà không tăng proportionally chi phí API — một lợi thế cực kỳ quan trọng khi throughput tăng cao.
Yếu Tố Bền Vững
Ít lần gọi LLM hơn đồng nghĩa với ít năng lượng tiêu thụ hơn — một điểm cộng ngày càng được quan tâm khi AI infrastructure mở rộng toàn cầu.
Semantic Caching vs. Prompt Caching: Đừng Nhầm Lẫn Hai Khái Niệm Này
Một điểm gây nhầm lẫn phổ biến là sự khác nhau giữa semantic caching và prompt caching. Đây là hai kỹ thuật khác nhau, hoạt động ở các tầng khác nhau:
- Semantic caching (application-level): Xảy ra trước khi gọi API. Ứng dụng của bạn tự quản lý cache này, so sánh ý nghĩa của query và trả về cached response nếu tìm thấy kết quả phù hợp.
- Prompt caching (API-level): Được cung cấp bởi Anthropic (từ tháng 8/2024) và OpenAI. Caching xảy ra tại tầng inference của model, lưu lại KV attention states của các prompt prefix lặp lại. Yêu cầu khớp chính xác tiền tố, và có thể giảm chi phí 50–90% cho system prompt dài được tái sử dụng.
Điểm quan trọng: hai kỹ thuật này bổ trợ cho nhau, không loại trừ nhau. Bạn hoàn toàn có thể dùng semantic caching ở application layer để lọc các query tương tự, đồng thời bật prompt caching ở API level để tiết kiệm chi phí xử lý system prompt dài.
Các Công Cụ và Framework Cho Semantic Caching
GPTCache (by Zilliz)
Thư viện open-source toàn diện nhất dành riêng cho semantic caching trong LLM systems. GPTCache hỗ trợ nhiều embedding model và vector store backend (FAISS, Milvus, Redis, Qdrant, Weaviate), tích hợp với LangChain, LlamaIndex, và OpenAI SDK. Đây là lựa chọn đầu tiên nên xem xét nếu bạn muốn kiểm soát toàn bộ pipeline.
LangChain Caching
LangChain cung cấp SemanticSimilarityExactMatchCache và nhiều abstraction khác, cho phép dễ dàng swap backend. Nếu bạn đã dùng LangChain trong ứng dụng, đây là cách tích hợp semantic caching nhanh nhất.
LlamaIndex và Redis Vector Library (RedisVL)
LlamaIndex có SemanticCache tích hợp sẵn trong infrastructure indexing và retrieval. RedisVL (Redis Vector Library) cung cấp class SemanticCache xây dựng trên Redis Stack — lý tưởng cho các team đã dùng Redis trong stack hiện tại.
Managed/Cloud Options
Nếu bạn không muốn tự quản lý infrastructure, các lựa chọn sau đáng cân nhắc:
- Upstash Semantic Cache: Serverless, pay-per-use, REST API đơn giản.
- Portkey và LiteLLM: LLM gateway với semantic caching middleware tích hợp sẵn.
- Helicone: Platform observability với caching và analytics dashboard.
Embedding Models Phổ Biến
- OpenAI text-embedding-3-small: Cân bằng tốt giữa hiệu năng và chi phí.
- Sentence Transformers (all-MiniLM-L6-v2): Open-source, nhanh, phù hợp cho prototyping.
- Cohere Embed: Mạnh cho multilingual use cases.
Chọn Vector Database Backend Phù Hợp
Đây là framework đơn giản để chọn vector database:
- Prototyping/local development: Dùng FAISS (in-memory, không cần server) hoặc Chroma (nhẹ, developer-friendly, dễ cài đặt).
- Production deployment: Chuyển sang Pinecone (managed, production-ready) hoặc





Post Comment
You must be logged in to post a comment.