Serverless vs Containers vs VMs: Real Trade-offs in 2026
Most comparisons of serverless, containers, and VMs are written by cloud vendors trying to sell you their preferred abstraction, or by tool advocates who’ve built their identity around a particular paradigm. The result is a landscape littered with benchmark cherries, idealized workloads, and conspicuously absent line items on the invoice. This post is an attempt to cut through that noise.
I’ve watched teams migrate to serverless to save money and end up with bills three times higher than their old container cluster. I’ve seen startups adopt Kubernetes because it felt “enterprise-grade,” then spend six months fighting YAML and never shipping product. And I’ve watched people dismiss VMs as legacy technology right before a compliance audit forced them back. In 2026, the stakes are high enough — and the options mature enough — that getting this decision wrong has real consequences. Let’s talk about the actual trade-offs.
A Quick Level-Set: What Each Paradigm Actually Is
Before diving into trade-offs, it’s worth being precise about what we’re comparing, because loose definitions lead to bad decisions.
Virtual Machines run a complete operating system on top of a hypervisor — software (or dedicated hardware, in AWS’s Nitro system) that tricks the guest OS into believing it owns physical resources. Each VM carries its own kernel, system libraries, and application stack. Boot times run from 30 seconds to several minutes. The resource overhead is real: a minimal Linux VM consumes 256MB to 1GB of RAM before your application touches a byte. AWS launched EC2 in 2006 on Xen hypervisors, and that model — renting a slice of a physical machine — defined cloud computing for nearly a decade.
Containers share the host OS kernel and use Linux primitives — namespaces for isolation and cgroups for resource limits — to create the illusion of separate environments. Docker made this accessible in 2013. Containers boot in milliseconds, carry minimal overhead, and package everything your app needs into a portable image. The tradeoff: that shared kernel is both the efficiency win and the security liability.
Serverless functions (FaaS) sit at the top of the abstraction ladder. You write a function, define what events trigger it, and the cloud provider handles literally everything else — servers, scaling, patching, networking. AWS Lambda launched in 2014 and introduced per-millisecond billing. Cold starts range from 100ms to several seconds. You never manage a server, which sounds like pure upside until you try to debug a distributed system made of hundreds of ephemeral functions.
The abstraction ladder is the key mental model here: more abstraction means less operational control, lower ops burden, and deeper vendor dependency. Each paradigm emerged to solve the previous one’s dominant pain point. That history matters when you’re deciding which pain you’d rather live with.
The Cost Trade-off Nobody Does the Math On
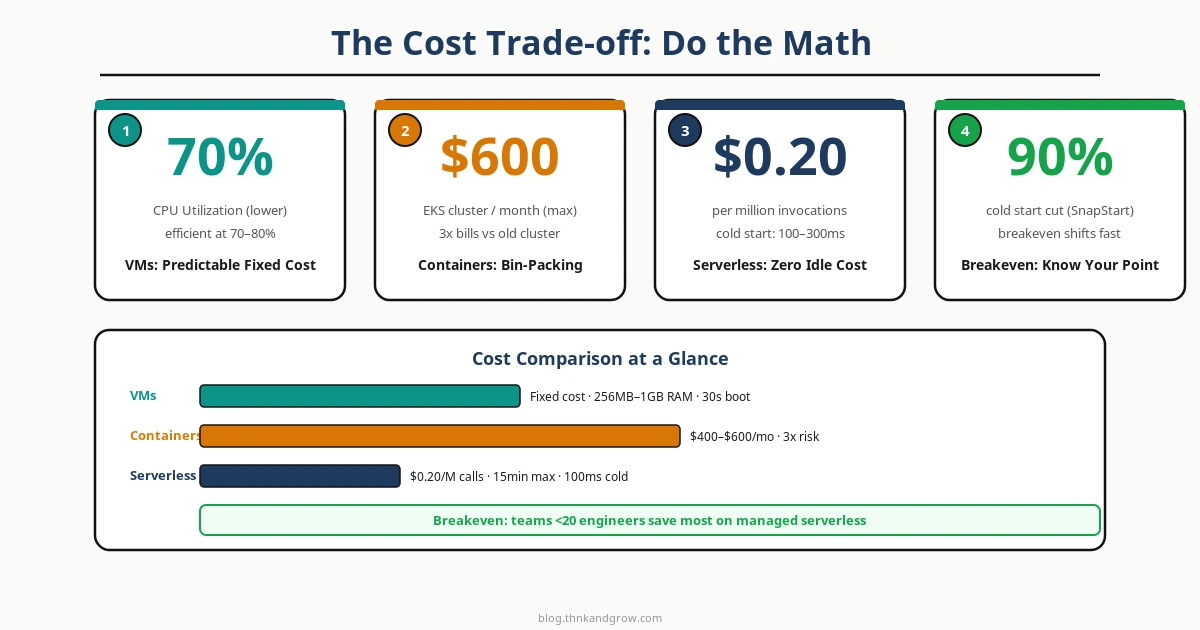
Here’s the uncomfortable truth: serverless is not inherently cheaper. It’s cheaper under specific conditions, and dramatically more expensive under others. Teams that skip the math and assume “pay per use = lower bills” are in for a surprise.
VMs have predictable, fixed costs. You pay for the instance whether it’s idle or saturated. This is wasteful at low utilization but highly efficient when you’re running at 70–80% CPU consistently. For steady, high-throughput workloads, a well-sized EC2 fleet is often the cheapest option per unit of compute.
Containers improve on VMs through bin-packing — running multiple workloads on shared nodes. But Kubernetes clusters carry hidden fixed costs: control plane fees, node overhead, persistent storage, load balancers, and the engineering time to operate the cluster. A three-node EKS cluster with supporting infrastructure often runs $400–600/month before a single line of application code executes.
Serverless billing is genuinely zero at zero load — that’s the real win. For spiky, unpredictable traffic with significant idle time, it’s hard to beat. But the math changes fast at scale. AWS Lambda charges approximately $0.20 per million invocations plus $0.0000166667 per GB-second. At high invocation volumes, this compounds quickly.
The concept to internalize is the break-even invocation threshold — the point at which your serverless bill exceeds what an equivalent container deployment would cost. For most workloads, this threshold is lower than teams expect. Calculate it before you commit, not after you’re locked in.
The Basecamp/37signals cloud exit narrative resonated in 2026 precisely because it made this math visible. DHH’s public accounting showed that at their scale, owned hardware dramatically undercut cloud costs. The lesson isn’t “leave the cloud” — it’s that cost assumptions need to be stress-tested at realistic scale. FinOps practices are now standard at mature engineering organizations for exactly this reason.
Performance and Latency: The Cold Start Elephant in the Room
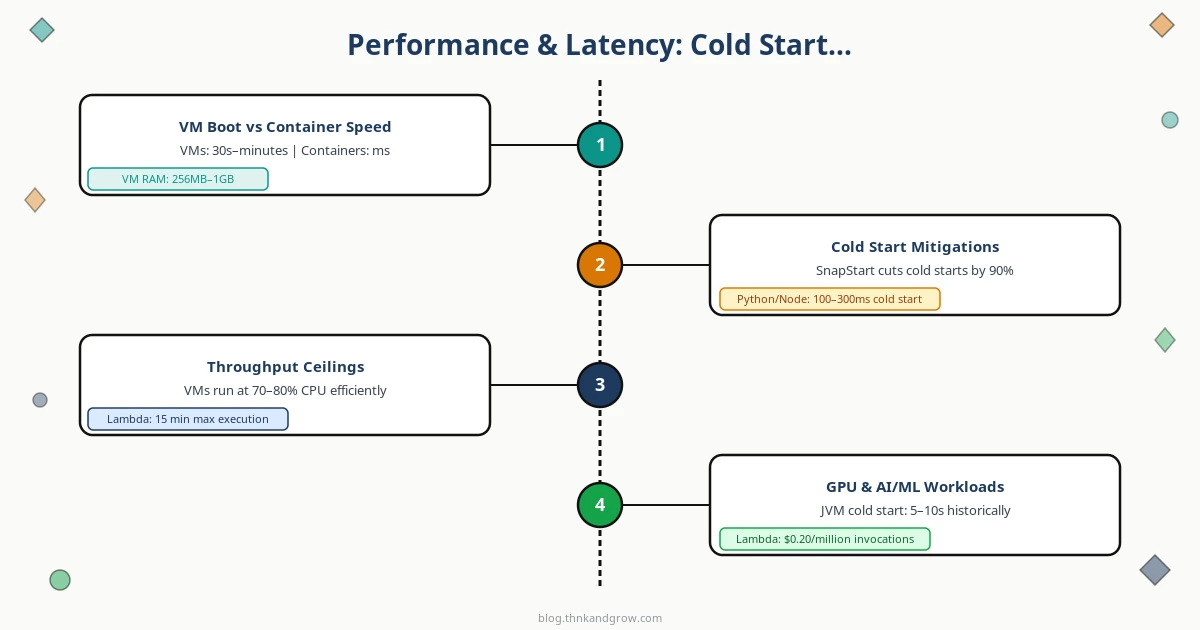
Cold starts are the serverless performance story that vendors minimize and engineers obsess over. When a Lambda function hasn’t been invoked recently, the provider must initialize a new execution environment: download the function package, start the runtime, run initialization code. For Python or Node.js, this might add 100–300ms. For JVM-based runtimes, it historically added 5–10 seconds — a user-facing disaster.
Mitigations exist but come with costs. AWS Lambda SnapStart (for Java workloads) pre-initializes execution environments and can reduce cold starts by up to 90% — a genuine engineering win. Provisioned Concurrency keeps functions warm but eliminates the zero-idle-cost advantage. Google Cloud Run’s minimum instances feature does the same. You’re essentially paying container-like costs to get serverless-like operations, which is a legitimate trade-off but not the “magic” billing model the marketing implies.
Containers start in seconds and VMs in minutes, but once running, both eliminate cold start variability entirely. For user-facing APIs with strict p99 latency requirements, this predictability often matters more than average-case performance.
GPU and AI/ML workloads add another dimension. Long-running training jobs — hours or days of continuous computation — are fundamentally incompatible with serverless execution time caps (Lambda maxes out at 15 minutes). These workloads belong on VMs or bare metal with dedicated GPU instances. However, serverless GPU inference is emerging as a legitimate pattern: platforms like Modal and Replicate offer per-invocation GPU execution that’s economically sensible for sporadic inference requests. This is one of the more interesting architectural developments of the past two years.
Operational Complexity: Who Actually Manages What
The honest framing here is the “undifferentiated heavy lifting” spectrum. VMs require you to manage everything: OS patching, kernel updates, network configuration, security group rules, auto-scaling policies, and monitoring. Containers shift that burden to orchestration — but Kubernetes is not simple. It’s a distributed systems platform with its own failure modes, upgrade cycles, and operational surface area that rivals the applications running on it.
Kubernetes fatigue is real in 2026. Teams that adopted K8s three or four years ago because it was the industry standard are now questioning whether the complexity overhead justifies the control it provides. Smaller engineering teams — under 20 engineers — are increasingly migrating to managed platforms like Render, Railway, and Fly.io, which offer container deployment without cluster management. This isn’t a step backward; it’s an honest assessment of organizational capacity.
Serverless offloads nearly all operational burden, but it introduces its own category of problems. Function sprawl — hundreds of Lambda functions with inconsistent naming, overlapping responsibilities, and undocumented triggers — is a genuine operational nightmare in mature serverless architectures. IAM permission creep, where functions accumulate over-permissive roles over time, is a security and audit problem. Distributed tracing across event-driven function chains requires investment in observability tooling (AWS X-Ray, Datadog, Honeycomb) that adds both cost and complexity. Debugging a stateless function that misbehaves only under specific event payloads, in an environment you can’t SSH into, is a genuinely different skill set.
The team skill requirement is often the deciding factor that gets ignored in architectural discussions. VMs need sysadmin and networking expertise. Containers need DevOps and Kubernetes knowledge. Serverless requires cloud-native architecture thinking — understanding event-driven patterns, idempotency, and eventual consistency at a conceptual level. The best technology is the one your team can operate reliably at 2 AM.
Vendor Lock-in and Portability: The Risk Nobody Prices In
Containers win on portability, and it’s not close. OCI-standard container images run on AWS, GCP, Azure, on-premises Kubernetes, and your laptop. The application stack is decoupled from the infrastructure. This is the closest the industry has come to write-once-run-anywhere, and it’s a meaningful architectural advantage when you’re thinking about three-to-five year infrastructure horizons.
Serverless is the most proprietary compute model available. Lambda trigger integrations, event source mappings, execution environment quirks, and the specific behavior of AWS SDK integrations are deeply AWS-specific. Migrating a mature Lambda-based architecture to Google Cloud Functions isn’t a lift-and-shift — it’s a rewrite. Teams should price this lock-in risk explicitly before committing.
VMs sit in the middle. AMIs are AWS-specific, but the OS, application stack, and configuration management tooling (Terraform, Ansible) are portable with effort. Moving a VM-based workload between clouds is painful but tractable.
The serverless containers category — AWS Fargate, Google Cloud Run, Azure Container Apps — represents an interesting middle ground: container portability with serverless operational model. You don’t manage clusters, but you deploy standard container images. The APIs and configuration are still cloud-specific, but the application artifact is portable. This is why serverless containers are the fastest-growing segment of the compute market right now.
Worth watching: WebAssembly (WASM) is emerging as a potential fourth paradigm with stronger portability and sandboxing promises than either containers or serverless. Cloudflare Workers and WasmEdge are early indicators of where this might go. It’s not production-ready for general-purpose workloads yet, but the architectural properties are compelling.
Security Trade-offs: Isolation, Attack Surface, and Compliance
VMs provide hardware-level isolation via the hypervisor boundary. A vulnerability in one VM cannot directly affect another on the same host. This makes VMs the preferred choice for compliance-heavy workloads — PCI-DSS, HIPAA, and FedRAMP environments often mandate VM-level isolation in their control frameworks.
Containers share the host kernel, which means a kernel exploit can theoretically escape the container boundary. In practice, this risk is managed through runtime security tools (Falco, gVisor) and hardened base images, but it’s a real attack surface that containers-on-VMs architectures (the most common production pattern) partially mitigate. Log4Shell demonstrated how deep dependency chains in containerized applications create supply chain risk that’s genuinely difficult to enumerate and patch quickly.
Serverless reduces the attack surface in one dimension — there are no persistent servers to patch, and the provider handles OS security — while expanding it in another. Function permission sprawl, third-party event source trust, and the implicit trust relationships in event-driven architectures create security challenges that are less visible but equally serious.
Architecture Fit: Matching the Paradigm to the Workload
The most useful framing is workload-first, not paradigm-first:
VMs: Monolithic applications, legacy systems requiring specific OS configurations, stateful workloads, GPU training jobs, compliance-sensitive systems requiring hardware isolation, and high-utilization steady-state compute.
Containers: Microservices architectures, CI/CD pipelines, polyglot environments, workloads requiring portability across environments, and teams with existing Kubernetes investment and the skills to operate it.
Serverless: Event-driven processing, webhooks, scheduled batch jobs, APIs with spiky or unpredictable traffic patterns, rapid prototyping, and integration glue code between services.
The most important architectural insight of 2026 is this: mature production systems use all three simultaneously. A typical architecture might run PostgreSQL on a VM for predictable performance and isolation, core application services on containers for portability and density, and event processing pipelines on Lambda for cost-effective burst handling. The skill isn’t picking one paradigm — it’s knowing which workload belongs on which model.
The Convergence Trend: Lines Are Blurring in 2026
The boundaries between these paradigms are genuinely eroding. Serverless containers are the clearest example: Cloud Run and Fargate give you container portability with serverless economics and zero cluster management. ARM/Graviton adoption is improving price-performance across both Lambda and EC2, though Apple Silicon’s M-series chips have created ARM/x86 architecture mismatches that complicate local container development in ways that are still being worked out.
Edge computing is adding a new dimension entirely. Cloudflare Workers (serverless at the edge), Fly.io (containers near users), and WASM runtimes are pushing compute to the network boundary with trade-off profiles that don’t map cleanly onto the traditional three-paradigm model. The paradigm you choose today may not exist in its current form in five years. Design your architecture for change, not for permanence.
A Decision Framework: How to Actually Choose
When evaluating a workload, work through these questions in order:
Traffic pattern: Is it steady or spiky? Steady favors VMs or containers. Spiky favors serverless.
Execution duration: Under 15 minutes and stateless? Serverless is viable. Long-running or stateful? Containers or VMs.
Latency sensitivity: Sub-100ms p99 requirements? Avoid cold starts — use containers or provisioned serverless.
Team skills: What can your team operate reliably? Don’t choose K8s if you don’t have the expertise to run it safely.
Cost math: Calculate the break-even invocation threshold at your expected scale before committing to serverless.
Exit strategy: How painful would migration be in three years? Weight portability accordingly.
Lê Hoàng Tâm (Tom Le) is a Software Engineer and Cloud Architect with over 10 years of experience. AWS Certified. Specializes in distributed systems, DevOps, and AI/ML integration. Founder of Th?nk And Grow — a platform sharing practical technology insights in Vietnamese. Passionate about building scalable systems and helping developers grow through real-world knowledge.





Post Comment
You must be logged in to post a comment.