[Mysql 8] Optimizing Snapshot Management Queries in TypeORM
When managing snapshots of items in a database, ensuring that only a limited number of recent snapshots are retained while older ones are removed is crucial for maintaining system performance and managing storage effectively. In this article, we’ll discuss how to optimize queries for this purpose using TypeORM, starting with a traditional approach and moving towards a more efficient solution using window functions.
The Main Problem: Retaining Only the Most Recent Snapshots
The primary challenge is to retain a maximum number of the most recent snapshots for each item and delete older snapshots that exceed this limit. This ensures that the dataset remains manageable and storage usage is optimized.
The Original Approach: Using a Subquery with COUNT(*)
In the initial approach, we use a subquery to count how many newer snapshots exist for each snapshot. This allows us to identify which snapshots are older than the maximum number we want to keep.
Here’s how the original query looks:
const snapshots = await this.snapshotRepo
.createQueryBuilder('snapshot')
.select('snapshot.id')
.where('snapshot.item_id IN (:...itemIds)', { itemIds })
.andWhere(`(
SELECT COUNT(*)
FROM snapshots AS sub
WHERE sub.item_id = snapshot.item_id
AND sub.created_at > snapshot.created_at
) >= :maxSnapshots`,
{ maxSnapshots }
)
.getMany();Example Result for Subquery
Consider an item with item_id = 123 and the following snapshots, ordered by created_at:
| snapshot_id | item_id | created_at |
|---|---|---|
| 1 | 123 | 2024-09-05 10:00:00 |
| 2 | 123 | 2024-09-04 12:00:00 |
| 3 | 123 | 2024-09-03 08:00:00 |
For each snapshot, the subquery counts how many snapshots exist with a created_at greater than the current snapshot. The results would be:
| snapshot_id | COUNT(*) (newer snapshots) |
|---|---|
| 1 | 0 |
| 2 | 1 |
| 3 | 2 |
If maxSnapshots = 2, only snapshot 3 is retained as it has 2 newer snapshots. Snapshots 1 and 2 would be filtered out.
The Problem with the Original Approach
While the original approach is effective, it becomes inefficient as the dataset grows. The subquery to count newer snapshots must be executed for each row in the result set, resulting in increased computational cost and slower performance for larger datasets.
The Optimized Approach: Using ROW_NUMBER() Window Function
To enhance performance, we switch to using the ROW_NUMBER() window function. This approach ranks snapshots for each item based on their creation date and helps us directly identify which snapshots are beyond the maximum number to keep.
Here’s the optimized query using ROW_NUMBER():
const snapshots = await this.snapshotRepo
.createQueryBuilder('snapshot')
.select('snapshot.id')
.where('snapshot.item_id IN (:...itemIds)', { itemIds })
.andWhere(
'(ROW_NUMBER() OVER (PARTITION BY snapshot.item_id ORDER BY snapshot.created_at DESC)) > :maxSnapshots',
{ maxSnapshots }
)
.getMany();Example Result with ROW_NUMBER()
Using the same dataset, the ROW_NUMBER() function would assign ranks based on created_at in descending order:
| snapshot_id | item_id | created_at | ROW_NUMBER() |
|---|---|---|---|
| 1 | 123 | 2024-09-05 10:00:00 | 1 |
| 2 | 123 | 2024-09-04 12:00:00 | 2 |
| 3 | 123 | 2024-09-03 08:00:00 | 3 |
If maxSnapshots = 2, the query retains snapshots with a ROW_NUMBER() greater than 2, which would be snapshot 3. Snapshots 1 and 2 are filtered out.
Why This Approach Is More Efficient
The ROW_NUMBER() approach processes the snapshots in a single pass, ranking them within each item group and filtering based on rank. This method avoids the repetitive execution of subqueries, leading to improved performance and scalability, especially for large datasets.
Conclusion
The challenge of retaining only the most recent snapshots while deleting older ones can be efficiently addressed using window functions like ROW_NUMBER(). By optimizing the query, we enhance performance and manageability of the dataset, ensuring that the application remains responsive and efficient as data volume grows.
Simple query that you can try on mysql 8
SQL:
CREATE TABLE snapshots (
id INT AUTO_INCREMENT PRIMARY KEY,
item_id INT NOT NULL,
created_at DATETIME NOT NULL,
INDEX idx_item_created (item_id, created_at)
);
-- Insert random snapshots
INSERT INTO snapshots (item_id, created_at)
VALUES
(123, '2024-09-01 10:00:00'),
(123, '2024-09-02 11:00:00'),
(123, '2024-09-03 12:00:00'),
(123, '2024-09-04 13:00:00'),
(123, '2024-09-05 14:00:00'),
(124, '2024-09-01 15:00:00'),
(124, '2024-09-02 16:00:00'),
(124, '2024-09-03 17:00:00'),
(124, '2024-09-04 18:00:00'),
(124, '2024-09-05 19:00:00'),
(125, '2024-09-01 20:00:00'),
(125, '2024-09-02 21:00:00'),
(125, '2024-09-03 22:00:00'),
(125, '2024-09-04 23:00:00'),
(125, '2024-09-05 00:00:00');OLD query:
SELECT s.id, s.item_id, created_at
FROM snapshots as s
WHERE s.item_id IN (123,124, 125)
AND (
SELECT COUNT(*)
FROM snapshots AS sub
WHERE sub.item_id = s.item_id
AND sub.created_at > s.created_at
) >= 2;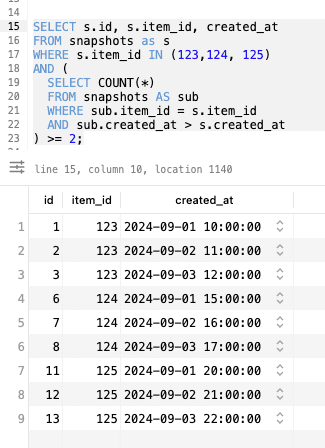
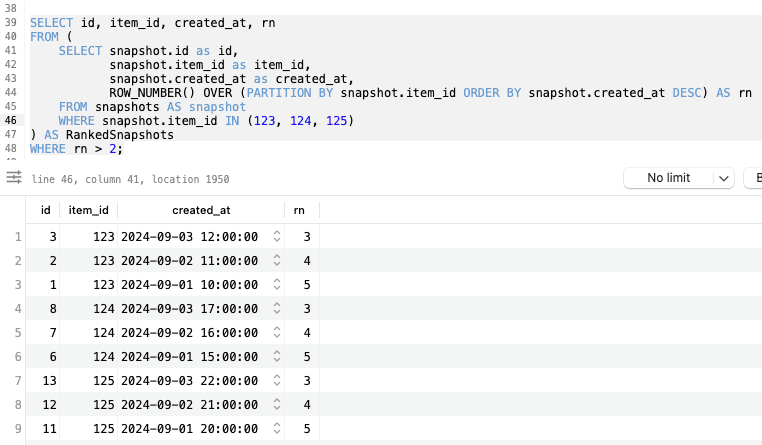
New Query:
SELECT id, item_id, created_at, rn
FROM (
SELECT snapshot.id as id,
snapshot.item_id as item_id,
snapshot.created_at as created_at,
ROW_NUMBER() OVER (PARTITION BY snapshot.item_id ORDER BY snapshot.created_at DESC) AS rn
FROM snapshots AS snapshot
WHERE snapshot.item_id IN (123, 124, 125)
) AS RankedSnapshots
WHERE rn > 2;
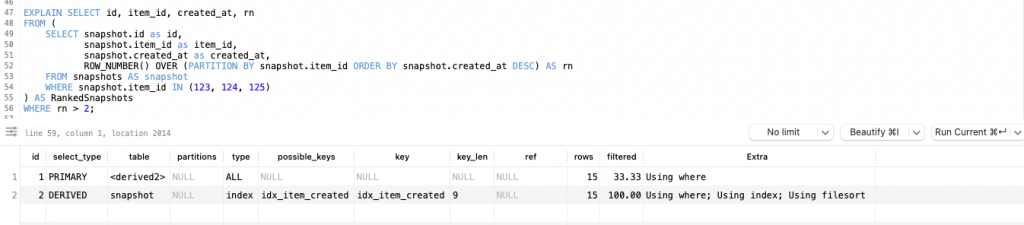
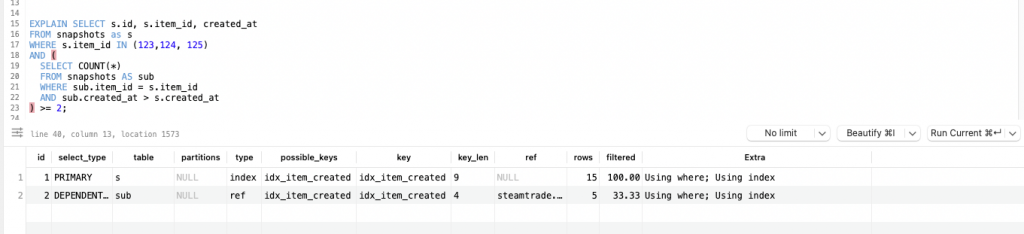
The performance of a query involving ROW_NUMBER() versus a COUNT() query can be influenced by several factors, and the EXPLAIN output alone might not provide a complete picture. Here’s why a ROW_NUMBER() query might sometimes appear quicker despite the EXPLAIN result indicating it could be less performant:
Factors Influencing Query Performance
- Execution Plan Complexity:
ROW_NUMBER()Query: This involves generating row numbers for each row and partitioning the result set. Although theEXPLAINmight indicate potential inefficiencies, the actual execution might benefit from optimizations or caching that reduce its impact.COUNT()Query: This typically requires counting rows that match certain criteria, which might involve scanning and aggregating data. If the data set is large, this can become costly, especially if not well-indexed.
- Data Distribution and Index Utilization:
- Index Efficiency: The
ROW_NUMBER()query uses indexes for sorting and partitioning, which can be efficient if the index is well-suited for the operations. If the data set is small or the index is particularly effective, the performance might be better than expected. - Count Query Overhead: A
COUNT()query, especially with a complexWHEREclause or without proper indexing, might face overhead from scanning large volumes of data or performing complex calculations.
- Index Efficiency: The
- Query Caching:
- Caching: If the results of the
ROW_NUMBER()query are cached or if the database engine can optimize the computation, the query might execute faster than anticipated. Caching mechanisms can significantly speed up queries, especially if the same query is run frequently.
- Caching: If the results of the
- Subquery Execution:
- Execution Context: The subquery in the
COUNT()query might involve additional overhead, such as scanning and processing rows to perform the count. Depending on the database engine and its optimizations, this can sometimes make theROW_NUMBER()query faster if the engine optimizes the ranking operation efficiently.
- Execution Context: The subquery in the
- Database Engine Optimizations:
- Engine Differences: Different database engines have varying levels of optimization for complex queries. The performance can also be influenced by how well the database engine handles operations like sorting and partitioning compared to aggregating counts.
- Query Plan Execution:
- Plan Choices: The actual execution might differ from the plan provided by
EXPLAIN. The database engine might choose an execution path that is not fully reflected in theEXPLAINoutput, especially for complex queries involving derived tables and window functions.
- Plan Choices: The actual execution might differ from the plan provided by
Read more: https://dev.mysql.com/doc/refman/8.4/en/window-functions-usage.html