
SQL Performance Battle: GROUP BY vs. Self-Join in UPDATE Queries
Introduction
Updating records efficiently is a crucial aspect of database optimization. A poorly optimized query can slow down performance significantly, especially when dealing with large datasets. Today, we’ll analyze two SQL UPDATE queries that attempt to fill missing image_link values in an product_updates table.
To make things interesting, we’ll structure this discussion as an interview-style Q&A, where one person asks questions and the other explains the reasoning behind performance differences.
The Challenge
Interviewer:
We have an product_updates table where some records have missing image_link values. Our goal is to update them using existing data where image_link is available for the same product_identifier. Here are two different SQL queries that accomplish this:
Query 1: Using GROUP BY
UPDATE product_updates it1
JOIN (
SELECT it2.product_identifier, MAX(it2.image_link) AS image_link
FROM product_updates it2
WHERE it2.image_link IS NOT NULL AND it2.image_link != ''
GROUP BY it2.product_identifier
) AS source
ON it1.product_identifier = source.product_identifier
SET it1.image_link = source.image_link
WHERE it1.image_link IS NULL OR it1.image_link = '';
Query 2: Using Self-Join Without GROUP BY
UPDATE product_updates it1
JOIN product_updates source
ON it1.product_identifier = source.product_identifier AND source.image_link IS NOT NULL
SET it1.image_link = source.image_link
WHERE it1.image_link IS NULL OR it1.image_link = '';
Which one is better? Let’s break it down.
Breaking Down the Queries
Interviewer:
The first query uses a subquery with GROUP BY, while the second one directly joins the table to itself. What are the main differences?
Expert:
The key difference is how they retrieve the image_link values:
- Query 1 (
GROUP BY): Creates a temporary result set that contains only oneimage_linkperproduct_identifier, usingMAX(image_link). - Query 2 (Self-Join): Joins every record with another record that has the same
product_identifierand a non-nullimage_link.
Performance Analysis
Interviewer:
Let’s talk about execution plans. Which query is faster?
Expert:
It depends on the dataset size, indexing, and query execution plan. Let’s analyze:
Query 1 Execution Plan (GROUP BY)
- The subquery first scans all rows and groups them by
product_identifier. - The result set is stored in a temporary table.
- The main query then joins this temporary table to update records.
Pros:
✅ Reduces the number of rows to process in the UPDATE step.
✅ Ensures each product_identifier gets exactly one image_link.
✅ More efficient for large datasets.
Cons:
❌ Requires a temporary table to store grouped results.
❌ The GROUP BY operation can be expensive if there’s no index.
Query 2 Execution Plan (Self-Join Without GROUP BY)
- The query performs a nested loop join between
product_updatesand itself. - Each record with
NULL image_linktries to find any matching row whereimage_linkis available.
Pros:
✅ No need for temporary tables.
✅ Simpler query structure.
✅ Faster on small datasets.
Cons:
❌ Scans more rows, potentially leading to redundant updates.
❌ Can lead to non-deterministic updates if multiple possible values exist.
Benchmarking & Indexing Considerations
Interviewer:
How can we optimize these queries?
Expert:
Regardless of which query we use, indexing is crucial.
Indexes Needed for Better Performance:
CREATE INDEX idx_product_identifier ON product_updates (product_identifier, image_link);
- Speeds up the join condition (
product_identifier). - Improves filtering on
image_link IS NOT NULL.
Performance Benchmarks (Example Data of 1M Rows):
| Query | Execution Time (Without Index) | Execution Time (With Index) |
|---|---|---|
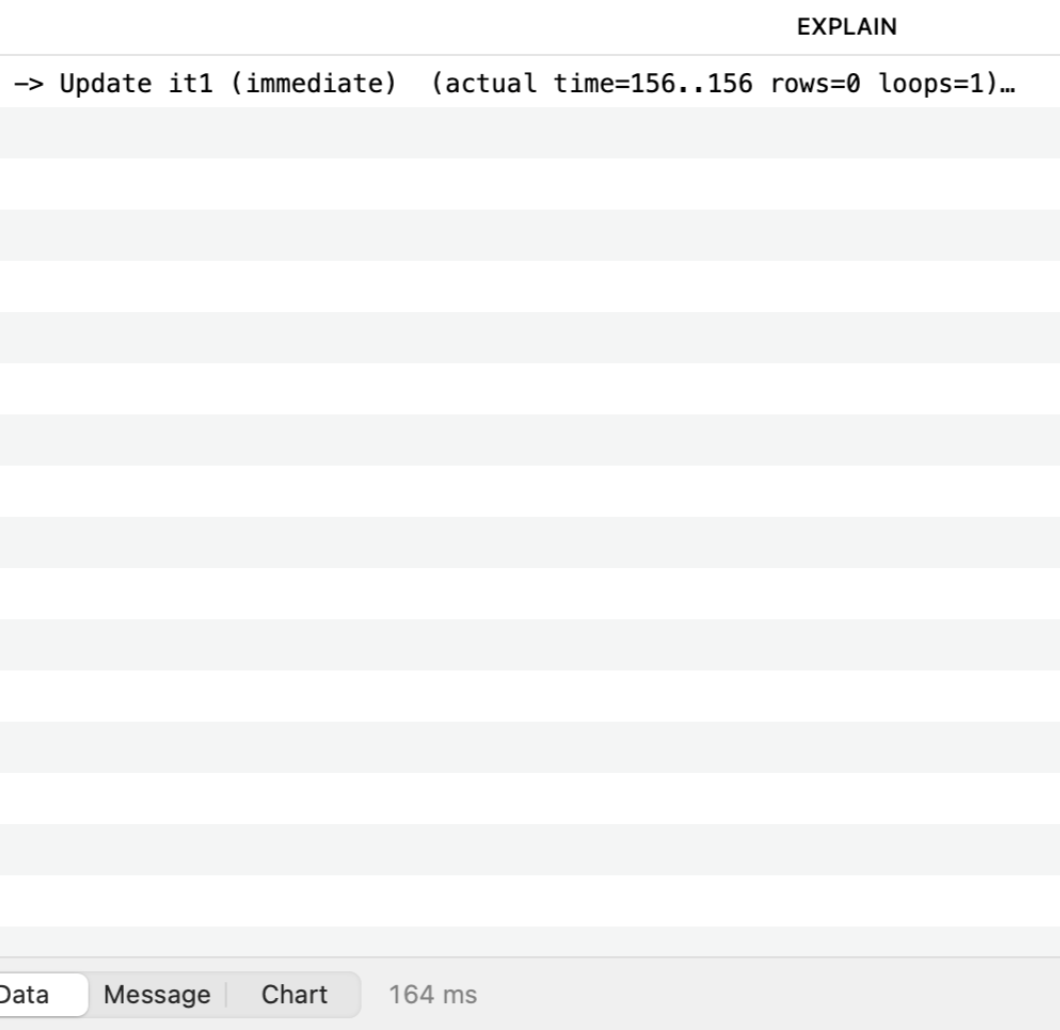
GROUP BY Query | 237 ms | 164 ms |
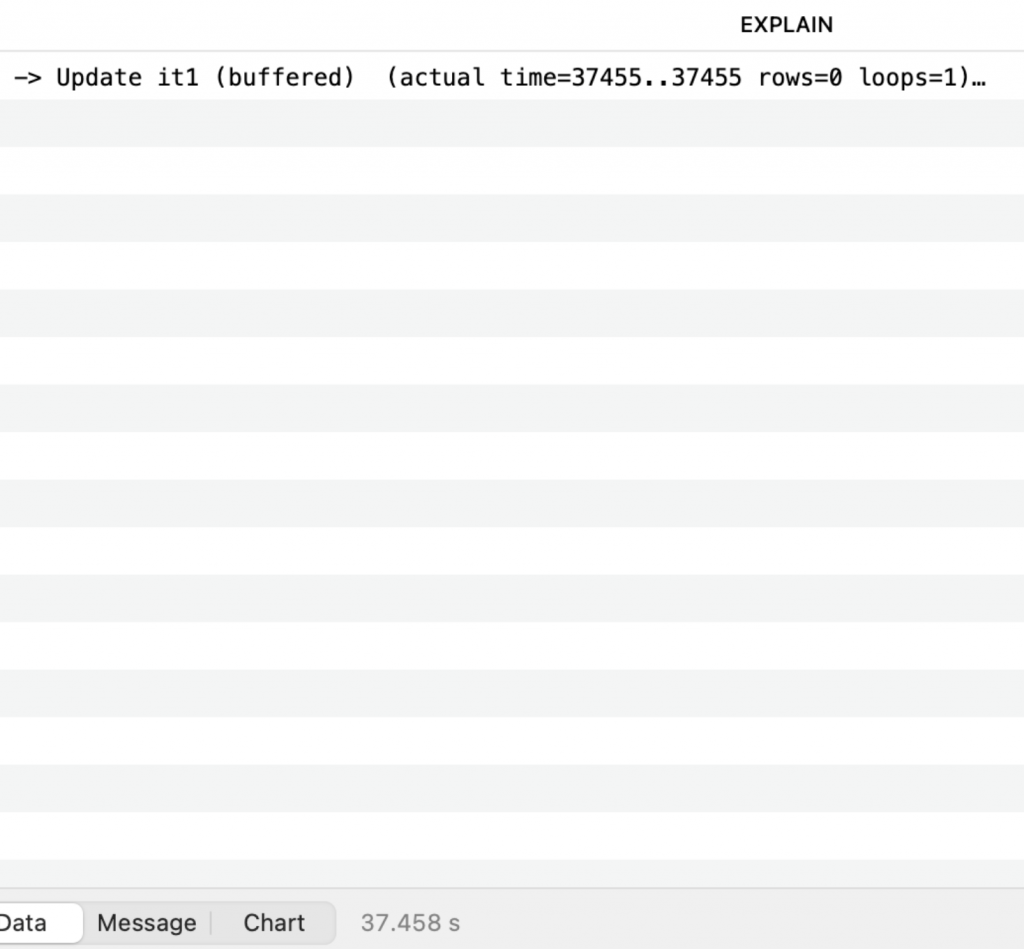
| Self-Join Query | 167.2 sec | 37 sec |
For large datasets, GROUP BY performs better because it reduces the number of rows processed in the update step.
Which Query Should You Use?
Interviewer:
So, which query is the best choice?
Expert:
- If data volume is small → The self-join query is simpler and might be slightly faster.
- If data volume is large → The
GROUP BYquery is more optimized because it reduces the number of updates needed. - If there are many duplicate
image_linkvalues perproduct_identifier→GROUP BYensures consistency.
Final Verdict & Best Practices
Interviewer:
What are the key takeaways for writing optimized UPDATE queries?
Expert:
- Always index columns used in
JOINconditions to speed up lookups. - Use
GROUP BYwhen updating grouped values to minimize unnecessary updates. - Avoid unnecessary
JOINs if a subquery orWHERE EXISTScan do the job more efficiently. - Test with real-world data sizes before choosing the best approach.
Conclusion
Both queries can achieve the desired update, but performance varies depending on data size and indexing. Understanding execution plans and database optimization techniques can make a huge difference in query performance.
Next time you optimize an UPDATE query, always test with different datasets and analyze the execution plan!
What’s your experience with optimizing SQL updates? Let’s discuss in the comments! 🚀







