Th?nk And Grow
https://blog.thnkandgrow.com/vi/
Let's Do It!Fri, 27 Mar 2026 08:38:59 +0000vi
hourly
1 https://wordpress.org/?v=6.9.4https://d1gj38atnczo72.cloudfront.net/wp-content/uploads/2024/04/18114102/cropped-thnkandgrow-logo-32x32.jpgTh?nk And Grow
https://blog.thnkandgrow.com/vi/
3232Cách Xây Dựng Hệ Thống AI Có Khả Năng Mở Rộng Năm 2026
https://blog.thnkandgrow.com/vi/cach-xay-dung-he-thong-ai-co-kha-nang-mo-rong-2026/
https://blog.thnkandgrow.com/vi/cach-xay-dung-he-thong-ai-co-kha-nang-mo-rong-2026/#respondFri, 27 Mar 2026 08:38:59 +0000https://blog.thnkandgrow.com/?p=3499Xây AI thì dễ, nhưng để nó chạy ổn định ở quy mô lớn lại là bài toán hoàn toàn khác. Bài viết này phân tích các kiến trúc chủ đạo năm 2026 — từ RAG, agent systems đến compound AI — cùng cách kiểm soát chi phí inference, độ trễ và observability trong môi trường production thực tế. Nếu bạn đang xây dựng hoặc mở rộng hệ thống AI, đây là nền tảng bạn không thể bỏ qua.
]]>Năm 2022, câu hỏi mà mọi team kỹ thuật đặt ra là: “Làm sao để model AI này hoạt động được?” Năm 2026, câu hỏi đó đã hoàn toàn thay đổi: “Làm sao để hệ thống AI này hoạt động ổn định, có thể mở rộng, và không đốt hết ngân sách compute trong vòng ba tháng?”
Đây là sự chuyển dịch căn bản mà bất kỳ engineer nào đang làm việc với AI production cần phải nhận ra. Getting a model to work — fine-tuning, prompting, evaluation — đó không còn là phần khó nhất nữa. Phần khó là xây dựng infrastructure xung quanh nó: data pipeline đáng tin cậy, serving layer có khả năng chịu tải, observability đủ sâu để phát hiện khi model bắt đầu “nói bậy” mà không có error log nào cảnh báo bạn.
Bài viết này dành cho các software engineer, ML engineer, và technical architect đang ở giai đoạn xây dựng hoặc scale AI-powered applications trong production. Chúng ta sẽ đi qua toàn bộ stack — từ data ingestion đến inference optimization, từ RAG architecture đến LLMOps — với góc nhìn thực tế, không phải lý thuyết hàn lâm.
Tại Sao AI System Design Khác Hoàn Toàn với Traditional Software Architecture
Traditional software có một đặc điểm quý giá mà chúng ta thường xuyên bỏ qua: nó fail loud. Khi có bug, bạn có stack trace. Khi service down, bạn có alert. Khi database query sai, bạn có error. AI systems không làm vậy.
AI systems fail silently. Model drift xảy ra từ từ trong nhiều tuần. Output quality giảm dần mà không có exception nào được throw. Một recommendation system có thể bắt đầu bias về một nhóm người dùng nhất định mà không có alarm nào kêu lên — cho đến khi báo chí đưa tin. Đây là lý do tại sao AI system design đòi hỏi một tư duy hoàn toàn khác.
Ngoài non-deterministic behavior, có một số concern hoàn toàn mới mà traditional software architecture không cần đối mặt:
Model lifecycle management: Model không phải code — nó có training data, versioning riêng, và cần retraining khi distribution của data thay đổi.
Feedback loops: Output của model ảnh hưởng đến input của model trong tương lai. Đây là một trong những nguồn gốc phổ biến nhất của production AI failures.
Compute cost management: OpenAI từng tốn khoảng 700,000 USD/ngày cho ChatGPT compute. Với các tổ chức nhỏ hơn, inference cost không được tối ưu có thể dễ dàng vượt quá toàn bộ infrastructure budget.
Regulatory compliance: EU AI Act đang có hiệu lực, yêu cầu explainability và auditability cho các AI systems ở nhiều lĩnh vực. Đây không còn là nice-to-have — đây là architectural requirement.
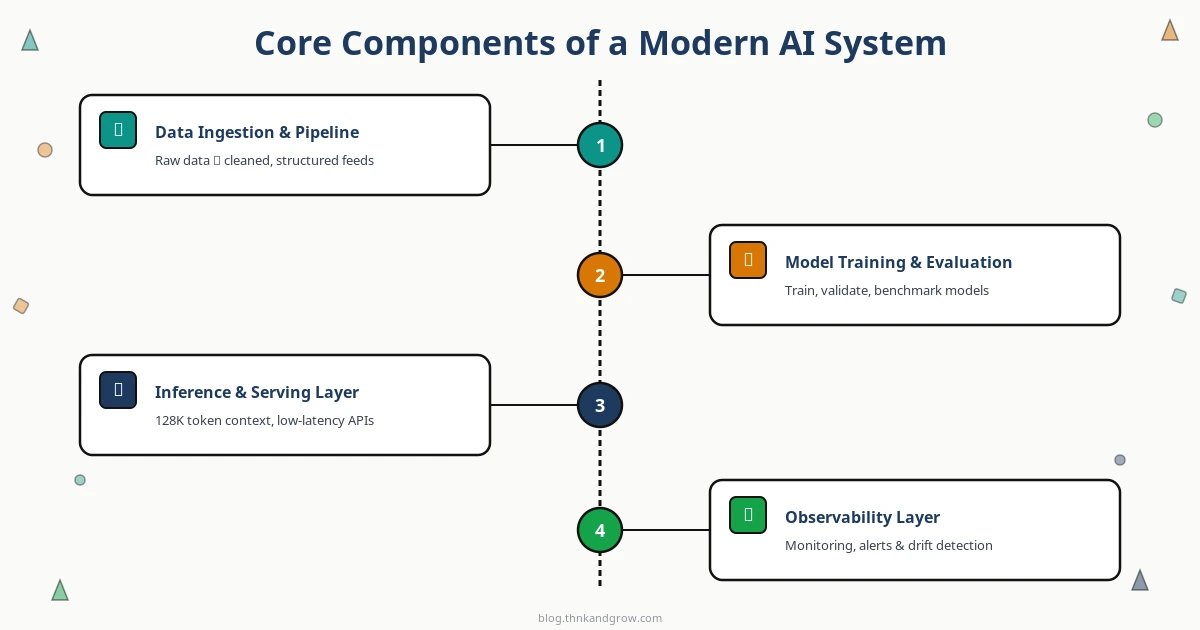
Các Thành Phần Cốt Lõi của Một AI System Hiện Đại
Một production AI system không phải là một model đứng một mình. Nó là một tập hợp các layer phối hợp với nhau, và mỗi layer đều có thể trở thành bottleneck nếu thiết kế kém.
Data Ingestion và Pipeline Layer
Mọi thứ bắt đầu từ data. Pipeline layer chịu trách nhiệm ingestion, cleaning, transformation, và versioning data ở quy mô lớn. Điểm quan trọng ở đây là data versioning — bạn cần biết chính xác model version X được train trên data nào, để có thể reproduce kết quả và debug khi cần. DVC (Data Version Control) và Delta Lake là hai công cụ phổ biến cho việc này.
Model Training và Evaluation Infrastructure
Experiment tracking không phải là luxury — đây là nền tảng của reproducibility. Nếu bạn không biết hyperparameter nào đã được dùng, data version nào đã được sử dụng, và environment nào đã chạy experiment đó, bạn không có một ML system, bạn có một black box. MLflow và Weights & Biases giải quyết vấn đề này, kết hợp với model registry để quản lý vòng đời của model.
Inference và Serving Layer
Đây là nơi mà các trade-off trở nên rõ ràng nhất. Latency thấp hay throughput cao? Self-hosted hay managed API? Real-time hay batch inference? Không có câu trả lời đúng cho tất cả — chỉ có câu trả lời phù hợp với use case cụ thể của bạn.
Observability Layer
Monitoring cho AI systems phải đi xa hơn traditional APM. Bạn cần track không chỉ latency và error rate, mà còn model drift (khi distribution của input data thay đổi so với training data), output quality degradation, và bias metrics. Langfuse và Arize AI là hai tool đáng chú ý trong không gian này.
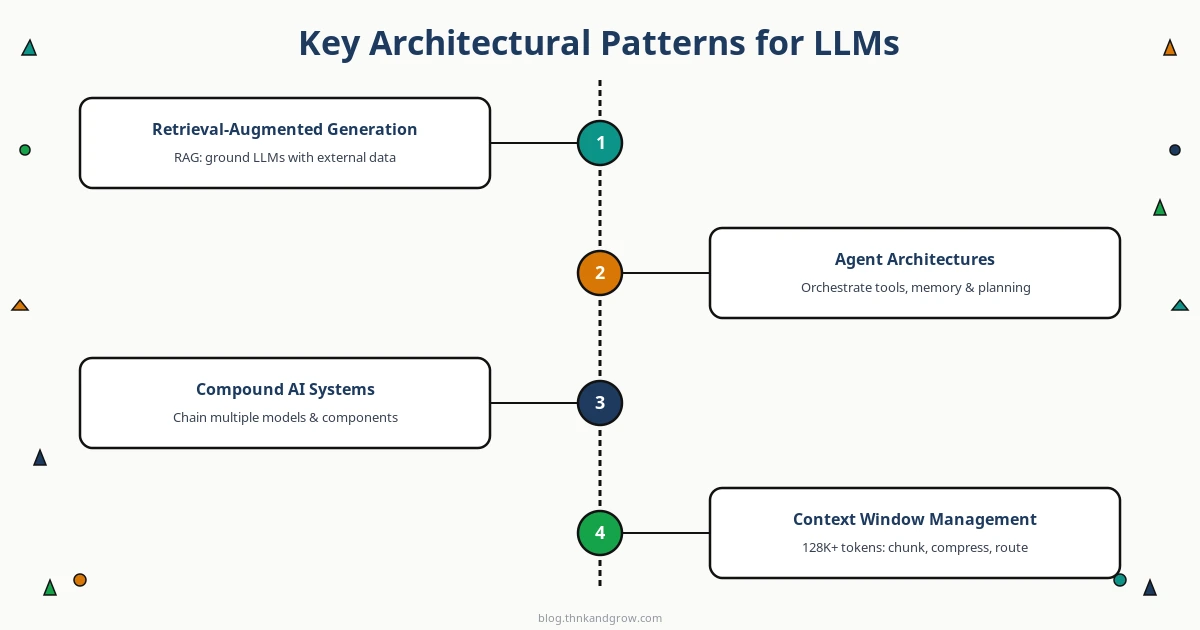
Các Architectural Pattern Chính cho LLM-Powered Applications
Sau hai năm production LLM deployments, ngành đã hội tụ về một số pattern đã được chứng minh. Đây không phải là trend — đây là engineering best practices.
Retrieval-Augmented Generation (RAG)
RAG là pattern phổ biến nhất cho enterprise LLM applications, và có lý do chính đáng. Thay vì cố gắng nhét toàn bộ knowledge vào weights của model (tốn kém, chậm, và không thể cập nhật real-time), RAG tách biệt knowledge store ra ngoài và retrieve relevant context tại inference time.
Architecture cơ bản: user query được embed thành vector, tìm kiếm trong vector database để lấy relevant documents, sau đó documents này được đưa vào context window của LLM cùng với query gốc. Kết quả là responses được “grounded” trong actual data của bạn, không phải hallucination.
Lựa chọn vector database phụ thuộc vào scale và existing stack: Pinecone cho managed simplicity, Qdrant cho performance cao với self-hosted, pgvector nếu bạn đã có Postgres và muốn giảm operational complexity.
Agent Architectures
Agent systems cho phép LLM không chỉ generate text mà còn thực hiện hành động: gọi API, chạy code, tìm kiếm web, query database. Đây là paradigm shift quan trọng, nhưng cũng đi kèm với complexity đáng kể về state management, error handling, và safety guardrails.
Một agent architecture điển hình sử dụng một “reasoning loop” — thường là ReAct (Reason + Act) pattern — trong đó LLM lần lượt suy nghĩ, chọn tool, thực thi, quan sát kết quả, và lặp lại. CrewAI và AutoGen của Microsoft là hai framework đáng để xem xét cho multi-agent scenarios.
Compound AI Systems
Thuật ngữ này được BAIR (Berkeley AI Research) và Databricks popularize năm 2024. Compound AI systems chain nhiều models, retrievers, và tools lại với nhau trong một unified workflow. Ví dụ: một document processing pipeline có thể dùng một vision model để extract text từ PDF, một classifier để categorize document, và một LLM để generate summary — tất cả orchestrated trong một single pipeline.
Context Window Management
Với context windows lên đến 1 triệu tokens, người ta dễ có xu hướng “nhét hết vào đó cho chắc.” Đây là sai lầm tốn kém. Mỗi token trong context window đều có cost — cả về latency lẫn tiền. Các chiến lược như sliding window, hierarchical summarization, và selective context injection là những kỹ thuật cần nắm vững.
Lựa Chọn Tools và Infrastructure Stack Phù Hợp
Không có stack nào là tốt nhất cho tất cả. Nhưng có một số nguyên tắc để lựa chọn.
Về cloud platforms: AWS Bedrock và Google Vertex AI phù hợp cho teams muốn managed experience với nhiều model choices. Azure OpenAI Service là lựa chọn tự nhiên nếu tổ chức đã deep trong Microsoft ecosystem. Databricks nổi bật nếu bạn có heavy data engineering workloads cần kết hợp với ML.
Về model serving engines: vLLM hiện là de facto standard cho open-source LLM serving, nhờ PagedAttention giúp quản lý GPU memory hiệu quả hơn đáng kể. TensorRT-LLM của NVIDIA cho throughput tối đa nếu bạn đang chạy trên NVIDIA GPUs. Ray Serve phù hợp cho complex inference graphs với nhiều models.
Về orchestration frameworks: LangChain vẫn là lựa chọn phổ biến nhất nhờ ecosystem rộng, nhưng DSPy của Stanford đang được chú ý nhiều cho các teams muốn optimize prompts một cách có hệ thống thay vì hand-craft. LlamaIndex tập trung hơn vào RAG pipelines và thường là lựa chọn tốt hơn cho document-heavy applications.
MLOps và LLMOps: Giữ Cho AI Systems Khỏe Mạnh trong Production
Đây là phần mà nhiều teams bỏ qua vội vàng để ship sản phẩm, rồi hối hận sau đó. MLOps không phải là overhead — đây là insurance policy cho production AI systems của bạn.
Experiment tracking và model versioning phải được thiết lập từ ngày đầu, không phải sau khi đã có vấn đề. MLflow là lựa chọn open-source mạnh mẽ; Weights & Biases cung cấp UX tốt hơn và collaboration features nếu budget cho phép.
Feature stores giải quyết một vấn đề cụ thể nhưng quan trọng: đảm bảo rằng features được tính toán theo cùng một cách trong cả training lẫn serving. Training-serving skew — khi features ở training time khác với features ở inference time — là một trong những nguyên nhân phổ biến nhất của mysterious model degradation.
Continuous monitoring cần được thiết kế vào system từ đầu. Với LLM applications, điều này bao gồm cả việc track output quality thông qua LLM-as-judge patterns — dùng một LLM khác để evaluate output của LLM chính theo các tiêu chí được định nghĩa trước.
Retraining pipelines đóng vòng lặp quan trọng nhất: đưa production signals (user feedback, correction data, performance metrics) trở lại quá trình training để model liên tục cải thiện. Đây là điểm khác biệt giữa một AI system stagnant và một AI system thực sự learning.
Thiết Kế Cho Cost, Latency, và Scale
Đây là phần kỹ thuật nhất và cũng là nơi mà quyết định thiết kế có tác động tài chính trực tiếp nhất.
Inference cost optimization có nhiều lever khác nhau. Quantization (giảm precision của model weights từ FP16 xuống INT8 hoặc INT4) có thể giảm memory footprint và tăng throughput đáng kể với minimal quality loss. Speculative decoding — dùng một draft model nhỏ hơn để generate tokens, sau đó verify bằng model lớn — giảm latency mà không ảnh hưởng đến output quality. Semantic caching (cache responses cho các queries tương tự nhau về mặt ngữ nghĩa) có thể giảm API costs lên đến 40-60% cho nhiều use cases.
AI Gateways như Kong AI Gateway, Portkey, và LiteLLM đang trở thành một layer quan trọng trong production stacks. Chúng cung cấp rate limiting, intelligent routing giữa các LLM providers, cost tracking, và fallback logic — tất cả trong một single control plane.
Edge AI là một lựa chọn đáng xem xét nghiêm túc cho các use cases nhạy cảm về latency hoặc privacy. Apple Core ML và Gemini Nano cho phép inference trực tiếp trên device, loại bỏ hoàn toàn network round-trip và giữ data trên thiết bị của người dùng.
Synchronous vs. asynchronous inference là một trong những quyết định architectural quan trọng nhất. Không phải mọi AI request đều cần real-time response. Batch processing cho document analysis, async queues cho background AI tasks — những pattern này có thể giảm infrastructure cost đáng kể bằng cách cho phép better GPU utilization.
Các Xu Hướng Đang Định Hình AI System Design Năm 2026
Mixture of Experts (MoE) đang thay đổi cách chúng ta nghĩ về inference infrastructure. Thay vì activate toàn bộ model cho mỗi token, MoE chỉ activate một subset của “expert” networks. Điều này có nghĩa là model có thể lớn hơn nhiều về tổng số parameters nhưng inference cost không tăng tương ứng — nhưng đòi hỏi infrastructure ph
]]>https://blog.thnkandgrow.com/vi/cach-xay-dung-he-thong-ai-co-kha-nang-mo-rong-2026/feed/0Semantic Caching trong Hệ thống LLM: Hướng Dẫn cho Người Mới
https://blog.thnkandgrow.com/vi/semantic-caching-trong-he-thong-llm-huong-dan-nguoi-moi/
https://blog.thnkandgrow.com/vi/semantic-caching-trong-he-thong-llm-huong-dan-nguoi-moi/#respondWed, 25 Mar 2026 16:51:50 +0000https://blog.thnkandgrow.com/?p=3485Gọi API LLM mỗi lần có câu hỏi tương tự nhau — bạn đang đốt tiền không cần thiết. Bài viết này giải thích cách semantic caching hoạt động dựa trên vector embeddings để nhận diện câu hỏi cùng nghĩa, cách chỉnh ngưỡng similarity cho phù hợp, và cách triển khai với các công cụ như GPTCache hay LangChain mà không cần chuyên môn ML sâu. Đây là kỹ thuật tối ưu chi phí thực tế nhất cho bất kỳ ứng dụng LLM nào có lượng truy vấn lặp
]]>Vì Sao LLM API Của Bạn Đang “Đốt Tiền” Mỗi Ngày?
Hãy tưởng tượng bạn đang vận hành một chatbot hỗ trợ khách hàng được xây dựng trên GPT-4. Mỗi ngày, hàng trăm người dùng gõ vào những câu hỏi như “Làm sao để đổi mật khẩu?”, “Cách đổi password?”, “Tôi muốn thay đổi mật khẩu tài khoản”, “Reset password như thế nào?”… Về mặt kỹ thuật, đây là bốn câu hỏi khác nhau. Nhưng về mặt ý nghĩa, chúng hoàn toàn giống nhau.
Nếu hệ thống của bạn gọi LLM API cho mỗi request, bạn đang trả tiền bốn lần cho cùng một câu trả lời. Nhân con số đó lên với hàng nghìn người dùng mỗi ngày, và bạn sẽ thấy chi phí API có thể leo thang nhanh đến mức đáng sợ — chưa kể mỗi lần gọi LLM còn mất từ 1 đến 10 giây để phản hồi.
Đây chính là vấn đề mà semantic caching được sinh ra để giải quyết. Không giống như traditional caching chỉ khớp chính xác từng ký tự, semantic caching hiểu được ý nghĩa đằng sau câu hỏi — và trả về kết quả đã lưu sẵn khi một câu hỏi tương tự xuất hiện, dù cách diễn đạt có khác nhau đến đâu.
Bài viết này sẽ giải thích semantic caching từ đầu: cách hoạt động, tại sao nó quan trọng, công cụ nào nên dùng, và làm thế nào để bắt đầu — ngay cả khi bạn chưa có kinh nghiệm sâu về ML infrastructure.
Semantic Caching Là Gì? (Và Khác Gì So Với Traditional Caching?)
Nói đơn giản: semantic caching là kỹ thuật lưu trữ phản hồi của LLM và tái sử dụng chúng khi có một câu hỏi có ý nghĩa tương tự được gửi đến — dù không cần giống từng chữ.
Hãy so sánh với traditional caching qua một ví dụ cụ thể:
Traditional cache: “What is the capital of France?” và “What’s France’s capital?” → hai cache miss, vì chuỗi ký tự khác nhau.
Semantic cache: Hai câu trên có cùng nghĩa → một cache hit, trả về cùng một câu trả lời đã lưu.
Dưới đây là bảng so sánh tổng quan:
Traditional Caching vs. Semantic Caching
Match type: Exact string match → Meaning/intent match Flexibility: Thấp → Cao Storage: Key-value (string → response) → Vector + key-value Lookup speed: O(1) hash lookup → Vector similarity search Miss rate: Cao (bất kỳ thay đổi nào = miss) → Thấp hơn (câu hỏi tương tự = hit) Infrastructure: Redis, Memcached → Vector DB + cache store
Rõ ràng, semantic caching đòi hỏi infrastructure phức tạp hơn — nhưng đổi lại, nó mang lại lợi ích vượt trội cho các ứng dụng LLM có lượng query lặp lại cao.
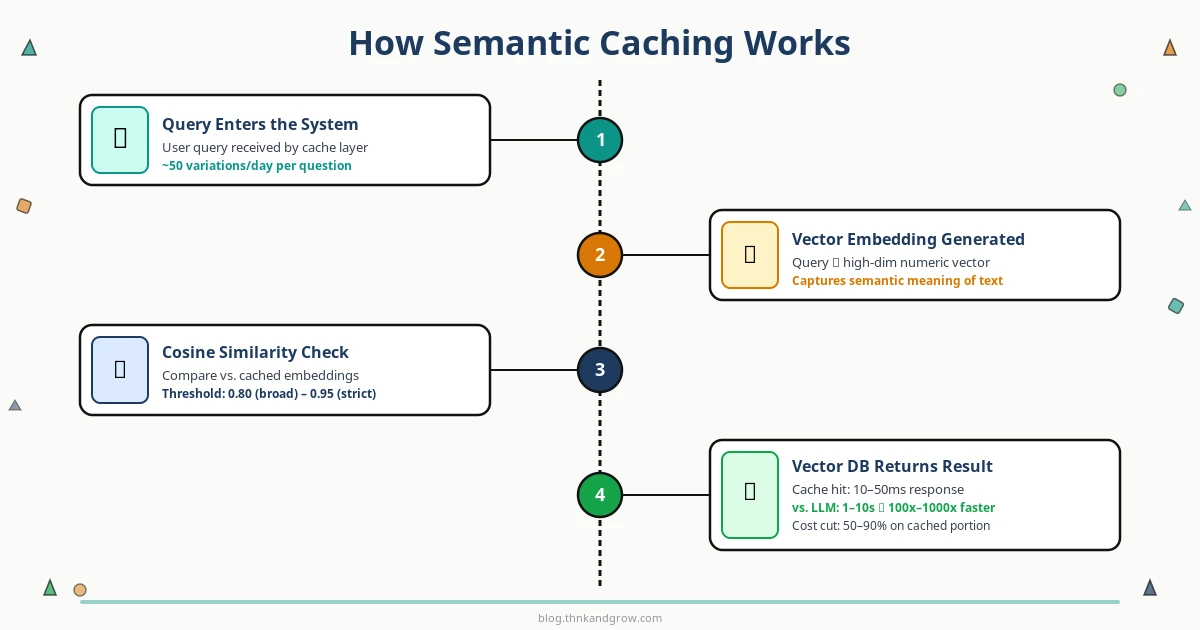
Semantic Caching Hoạt Động Như Thế Nào Bên Trong?
Quy trình hoạt động của semantic caching có thể chia thành các bước sau:
Query đến: Người dùng gửi một câu hỏi.
Embedding: Câu hỏi được chuyển đổi thành một vector số học (vector embedding) bằng một embedding model.
Similarity search: Vector mới được so sánh với các vector đã lưu trong vector database bằng cosine similarity hoặc các distance metric khác.
Cache hit hay miss: Nếu độ tương đồng vượt ngưỡng (similarity threshold) đã cấu hình → trả về cached response. Nếu không → gọi LLM API.
Lưu và trả về: Kết quả từ LLM được lưu vào cache (cùng với embedding của query) và trả về cho người dùng.
Vector Embeddings Là Gì?
Nếu bạn chưa quen với khái niệm này, hãy nghĩ đơn giản như sau: vector embedding là cách chuyển đổi một đoạn văn bản thành một danh sách các con số — ví dụ [0.12, -0.45, 0.87, ...] — sao cho các văn bản có nghĩa tương tự sẽ có các vector “gần nhau” trong không gian toán học.
Ví dụ: “Cách đổi mật khẩu” và “Làm sao reset password” sẽ có vector rất gần nhau, trong khi “Thời tiết hôm nay thế nào?” sẽ có vector ở xa hơn nhiều.
Cosine Similarity và Similarity Threshold
Cosine similarity đo góc giữa hai vector: giá trị từ 0 (hoàn toàn khác nhau) đến 1 (giống hệt nhau). Khi bạn cấu hình semantic cache, bạn sẽ đặt một similarity threshold — ví dụ 0.85. Nếu hai query có cosine similarity ≥ 0.85, hệ thống coi chúng là “đủ giống nhau” và trả về cached response.
Đây là thông số quan trọng nhất cần tinh chỉnh, và chúng ta sẽ bàn kỹ hơn ở phần Best Practices.
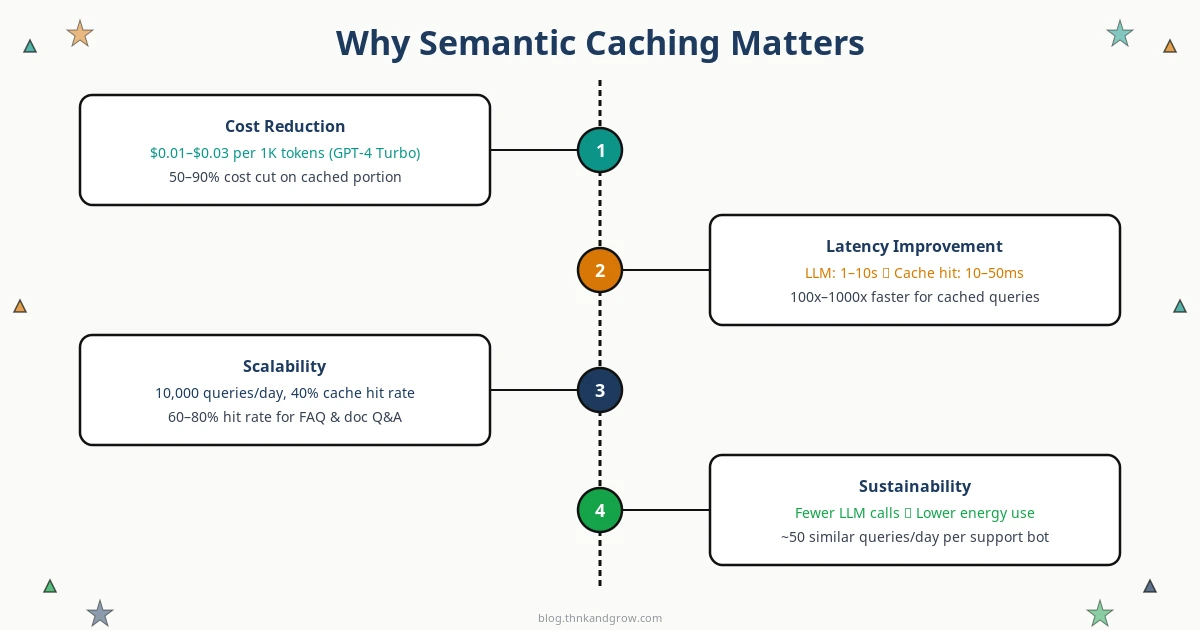
Tại Sao Semantic Caching Quan Trọng: Chi Phí, Tốc Độ, và Khả Năng Mở Rộng
Giảm Chi Phí API Đáng Kể
GPT-4 Turbo có giá khoảng $0.01–$0.03 mỗi 1.000 token. Với một ứng dụng FAQ bot nhận 10.000 query mỗi ngày, trong đó 60% là các câu hỏi tương tự nhau, bạn có thể tiết kiệm hàng trăm đô la mỗi tháng chỉ bằng cách không gọi API cho những câu hỏi đã có câu trả lời trong cache.
Cải Thiện Latency Đáng Kể
LLM inference thường mất 1–10 giây hoặc hơn tùy thuộc vào độ dài output. Một cache hit chỉ mất 10–50ms — nhanh hơn gần 100 lần. Với người dùng cuối, đây là sự khác biệt giữa trải nghiệm “mượt mà” và “chờ đợi mỏi mòn”.
Khả Năng Mở Rộng
Khi ứng dụng của bạn scale lên, chi phí API tăng tuyến tính nếu không có caching. Semantic caching cho phép bạn phục vụ nhiều người dùng đồng thời hơn mà không tăng proportionally chi phí API — một lợi thế cực kỳ quan trọng khi throughput tăng cao.
Yếu Tố Bền Vững
Ít lần gọi LLM hơn đồng nghĩa với ít năng lượng tiêu thụ hơn — một điểm cộng ngày càng được quan tâm khi AI infrastructure mở rộng toàn cầu.
Semantic Caching vs. Prompt Caching: Đừng Nhầm Lẫn Hai Khái Niệm Này
Một điểm gây nhầm lẫn phổ biến là sự khác nhau giữa semantic caching và prompt caching. Đây là hai kỹ thuật khác nhau, hoạt động ở các tầng khác nhau:
Semantic caching (application-level): Xảy ra trước khi gọi API. Ứng dụng của bạn tự quản lý cache này, so sánh ý nghĩa của query và trả về cached response nếu tìm thấy kết quả phù hợp.
Prompt caching (API-level): Được cung cấp bởi Anthropic (từ tháng 8/2024) và OpenAI. Caching xảy ra tại tầng inference của model, lưu lại KV attention states của các prompt prefix lặp lại. Yêu cầu khớp chính xác tiền tố, và có thể giảm chi phí 50–90% cho system prompt dài được tái sử dụng.
Điểm quan trọng: hai kỹ thuật này bổ trợ cho nhau, không loại trừ nhau. Bạn hoàn toàn có thể dùng semantic caching ở application layer để lọc các query tương tự, đồng thời bật prompt caching ở API level để tiết kiệm chi phí xử lý system prompt dài.
Các Công Cụ và Framework Cho Semantic Caching
GPTCache (by Zilliz)
Thư viện open-source toàn diện nhất dành riêng cho semantic caching trong LLM systems. GPTCache hỗ trợ nhiều embedding model và vector store backend (FAISS, Milvus, Redis, Qdrant, Weaviate), tích hợp với LangChain, LlamaIndex, và OpenAI SDK. Đây là lựa chọn đầu tiên nên xem xét nếu bạn muốn kiểm soát toàn bộ pipeline.
LangChain Caching
LangChain cung cấp SemanticSimilarityExactMatchCache và nhiều abstraction khác, cho phép dễ dàng swap backend. Nếu bạn đã dùng LangChain trong ứng dụng, đây là cách tích hợp semantic caching nhanh nhất.
LlamaIndex và Redis Vector Library (RedisVL)
LlamaIndex có SemanticCache tích hợp sẵn trong infrastructure indexing và retrieval. RedisVL (Redis Vector Library) cung cấp class SemanticCache xây dựng trên Redis Stack — lý tưởng cho các team đã dùng Redis trong stack hiện tại.
Managed/Cloud Options
Nếu bạn không muốn tự quản lý infrastructure, các lựa chọn sau đáng cân nhắc:
Upstash Semantic Cache: Serverless, pay-per-use, REST API đơn giản.
Portkey và LiteLLM: LLM gateway với semantic caching middleware tích hợp sẵn.
Helicone: Platform observability với caching và analytics dashboard.
Embedding Models Phổ Biến
OpenAI text-embedding-3-small: Cân bằng tốt giữa hiệu năng và chi phí.
Sentence Transformers (all-MiniLM-L6-v2): Open-source, nhanh, phù hợp cho prototyping.
Cohere Embed: Mạnh cho multilingual use cases.
Chọn Vector Database Backend Phù Hợp
Đây là framework đơn giản để chọn vector database:
Prototyping/local development: Dùng FAISS (in-memory, không cần server) hoặc Chroma (nhẹ, developer-friendly, dễ cài đặt).
Production deployment: Chuyển sang Pinecone (managed, production-ready) hoặc
https://blog.thnkandgrow.com/vi/semantic-caching-trong-he-thong-llm-huong-dan-nguoi-moi/feed/0Serverless, Container hay VM: Đánh Đổi Thật Sự Là Gì?
https://blog.thnkandgrow.com/vi/serverless-container-hay-vm-danh-doi-that-su/
https://blog.thnkandgrow.com/vi/serverless-container-hay-vm-danh-doi-that-su/#respondWed, 25 Mar 2026 01:56:56 +0000https://blog.thnkandgrow.com/?p=3478Serverless rẻ hơn? Chưa chắc — và đó chỉ là một trong nhiều quan niệm cần xem lại. Bài viết phân tích thẳng thắn điểm mạnh, điểm yếu và ngưỡng hòa vốn thực tế của từng mô hình compute, kể cả lý do VM vẫn chưa lỗi thời và tại sao serverless container đang là lựa chọn tăng trưởng nhanh nhất năm 2026. Nếu bạn đang ra quyết định hạ tầng, đây là góc nhìn trung lập bạn cần trước khi cam kết.
]]>Hầu hết các bài viết so sánh Serverless, Containers và VMs đều được viết bởi cloud vendor hoặc những người có lợi ích từ một công nghệ cụ thể. Bạn sẽ thấy những biểu đồ đẹp đẽ, những con số ấn tượng, nhưng hiếm khi thấy ai nói thẳng: “Chúng tôi đã dùng Serverless và hóa đơn tháng đó tăng gấp 5 lần” hay “Kubernetes đã giết chết năng suất của team chúng tôi trong 6 tháng.”
Là một kỹ sư đã từng bị hype đốt cháy nhiều lần, tôi muốn viết bài này theo cách khác — không có marketing, không có vendor bias, chỉ là những đánh đổi thực sự mà bạn cần hiểu trước khi đưa ra quyết định kiến trúc quan trọng nhất cho hệ thống của mình trong năm 2026.
Định Nghĩa Lại Từ Đầu: Ba Paradigm Thực Sự Là Gì?
Trước khi đi vào trade-off, hãy đảm bảo chúng ta đang nói về cùng một thứ.
Virtual Machines (VMs) là phần mềm mô phỏng một máy tính vật lý hoàn chỉnh, chạy trên hypervisor. Mỗi VM có một OS kernel riêng, system libraries riêng, và hoàn toàn tin rằng nó đang sở hữu phần cứng dành riêng. Boot time từ 30 giây đến vài phút. Overhead đáng kể — một Linux VM tối giản vẫn tiêu tốn 256MB–1GB RAM chỉ cho OS. AWS ra mắt EC2 năm 2006, và đó là lúc cloud computing thực sự bắt đầu.
Containers dùng OS-level virtualization thông qua Linux kernel features: namespaces để cô lập process/network/filesystem, và cgroups để giới hạn tài nguyên. Chúng chia sẻ host OS kernel — không cần guest OS. Docker phổ biến hóa containers năm 2013, Kubernetes trở thành chuẩn orchestration vào 2017–2018. Boot time: milliseconds đến vài giây. Overhead tối thiểu — một container có thể chạy với chỉ 4–10MB memory overhead.
Serverless (FaaS) là mức abstraction cao nhất — developer viết functions, cloud provider quản lý toàn bộ infrastructure. Event-driven, billing theo từng invocation và từng millisecond thực thi. AWS Lambda ra mắt năm 2014 và thay đổi cách chúng ta nghĩ về compute. Cold start từ 100ms đến vài giây tùy runtime.
Nguyên tắc cốt lõi cần nhớ: abstraction ladder càng cao thì càng ít control, càng ít ops burden, và càng phụ thuộc vào vendor nhiều hơn. Không có cái nào “tốt hơn” — chỉ có cái nào phù hợp hơn với bài toán cụ thể của bạn.
Chi Phí: Không Ai Chịu Ngồi Tính Toán Thật Sự
Đây là phần mà hầu hết các bài so sánh đều né tránh hoặc làm mờ nhạt.
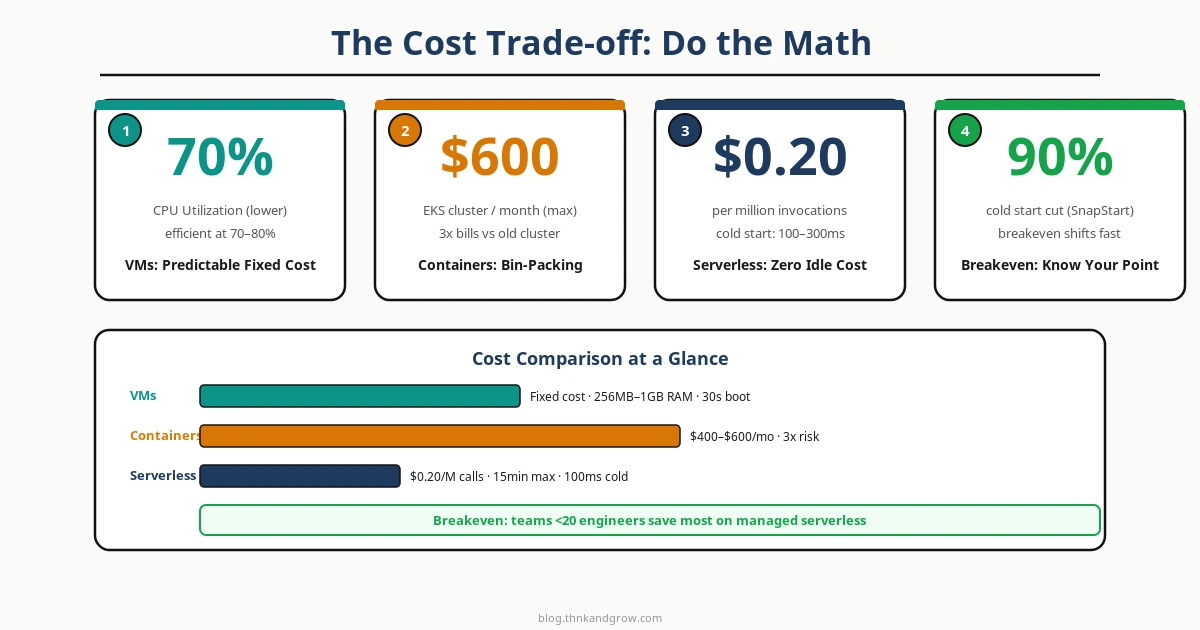
VMs có chi phí cố định và dự đoán được. Bạn trả tiền cho instance dù nó đang idle hay đang xử lý 100% CPU. Điều này nghe có vẻ lãng phí, nhưng với workload có utilization cao và ổn định, đây thực ra là mô hình rẻ nhất. Một c6g.xlarge trên AWS chạy 24/7 có giá khoảng $100/tháng — và nó xử lý được traffic liên tục mà không có bất kỳ surprise nào trên hóa đơn.
Containers trên Kubernetes hiệu quả hơn nhờ bin-packing — nhồi nhiều workload vào cùng một cluster. Nhưng đừng quên hidden fixed costs: bạn vẫn phải trả cho control plane, load balancers, persistent volumes, và ít nhất 2–3 worker nodes để đảm bảo high availability. Với team nhỏ, Kubernetes cluster overhead có thể chiếm $300–500/tháng trước khi bạn chạy bất kỳ workload thực sự nào.
Serverless nghe có vẻ ma thuật: zero idle cost, chỉ trả khi dùng. Và đúng là vậy — ở quy mô nhỏ. Vấn đề xảy ra khi bạn scale.
Ví dụ thực tế: Một function Lambda xử lý 10 triệu invocations/tháng, mỗi lần chạy 200ms với 512MB memory. Chi phí: khoảng $16.70/tháng. Nghe rẻ. Nhưng nếu bạn có 500 triệu invocations/tháng? Chi phí nhảy lên $835/tháng — trong khi một container trên Fargate hoặc một EC2 instance có thể xử lý throughput tương đương với $80–120/tháng.
Đây chính là khái niệm “break-even invocation threshold” — điểm mà Serverless trở nên đắt hơn Containers. Câu chuyện Basecamp/37signals rời bỏ cloud và tiết kiệm hàng triệu đô la đã minh chứng rõ ràng: ở quy mô đủ lớn, mô hình billing của cloud-native không còn có lợi nữa.
Trong bối cảnh FinOps năm 2026, các team đang buộc phải làm phép tính này một cách nghiêm túc. Nếu bạn chưa tính break-even threshold cho workload của mình, đó là rủi ro tài chính bạn đang bỏ qua.
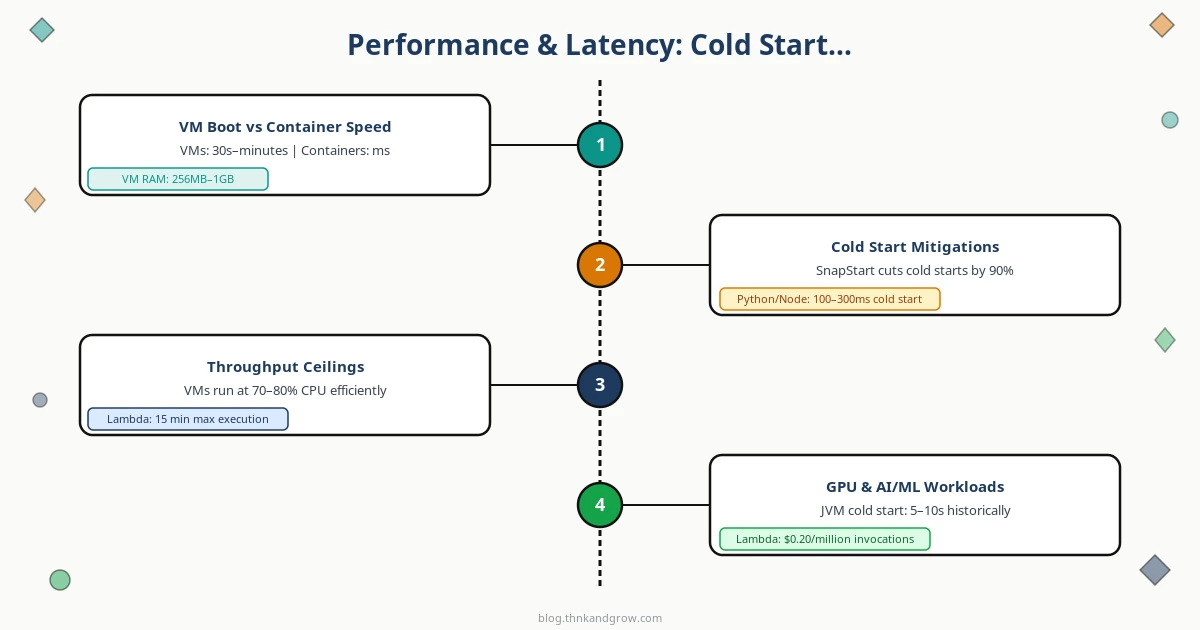
Performance và Latency: Con Voi Trong Phòng Tên Cold Start
VM boot time tính bằng phút. Container startup tính bằng giây. Serverless cold start từ 100ms đến vài giây — và đây là vấn đề nghiêm trọng với user-facing applications.
Tưởng tượng user click một button, request đến một Lambda function đang “ngủ”, và phải chờ 2–3 giây chỉ để function khởi động. Với Java runtime, cold start có thể lên đến 5–10 giây nếu không được tối ưu.
Các giải pháp mitigation đều tồn tại, nhưng đều có chi phí:
AWS Lambda SnapStart (cho Java): giảm cold start lên đến 90% bằng cách pre-initialize execution environment. Tốt, nhưng chỉ cho Java và có giới hạn.
Provisioned Concurrency: giữ một số lượng function instances luôn “warm”. Hiệu quả, nhưng bạn đang trả tiền idle — đúng cái bạn muốn tránh khi chọn Serverless.
Cloud Run minimum instances: tương tự, luôn giữ ít nhất một container chạy. Lại là chi phí cố định.
Về throughput ceilings: VMs có thể được tune cho raw performance — bạn có thể tối ưu network stack, memory allocation, CPU affinity. Serverless có concurrency limits (mặc định 1000 concurrent executions trên Lambda) và execution time caps (15 phút tối đa). Với long-running jobs, Serverless đơn giản là không phải lựa chọn.
Với GPU và AI/ML workloads — đây là lĩnh vực mà VMs và bare metal vẫn thống trị tuyệt đối cho training jobs. Serverless GPU functions (Modal, Replicate) đang nổi lên cho inference workloads ngắn hạn, nhưng vẫn còn nhiều hạn chế về memory và execution time.
Operational Complexity: Ai Thực Sự Quản Lý Cái Gì?
Hãy thành thật về “undifferentiated heavy lifting” spectrum:
VMs yêu cầu bạn tự quản lý toàn bộ: OS patching, network configuration, security groups, auto-scaling policies, load balancer setup, và monitoring. Cần sysadmin expertise thực sự. Nhưng bạn có full control — không có gì là hộp đen.
Containers trên Kubernetes shift ops burden sang orchestration layer. Và Kubernetes không hề đơn giản. Năm 2026, “Kubernetes fatigue” là có thật — các team nhỏ đang đặt câu hỏi nghiêm túc liệu việc maintain một K8s cluster có xứng đáng với overhead không. Bạn cần hiểu Deployments, Services, Ingress controllers, RBAC, NetworkPolicies, PodDisruptionBudgets, HorizontalPodAutoscaler… danh sách cứ dài ra mãi. Đây là lý do tại sao Render, Railway, và Fly.io đang thu hút nhiều team hơn — họ cung cấp container deployment mà không cần bạn trở thành K8s expert.
Serverless offloads gần như mọi thứ về infrastructure. Nhưng nó tạo ra các vấn đề operational khác:
Function sprawl: Một dự án lớn có thể có hàng trăm Lambda functions, mỗi cái có IAM role riêng, environment variables riêng, và configuration riêng.
IAM permission creep: Mỗi function cần permissions cụ thể. Theo thời gian, nếu không được quản lý chặt, bạn sẽ có một mạng lưới permissions rối rắm không ai hiểu rõ.
Distributed tracing nightmares: Debug một request đi qua 7 Lambda functions, 3 SQS queues, và 2 DynamoDB tables là một trải nghiệm không ai muốn lặp lại.
Vendor Lock-in và Portability: Rủi Ro Không Ai Định Giá
Containers win tuyệt đối về portability. OCI-standard images chạy được trên bất kỳ cloud nào, on-premises, hoặc laptop của bạn. Đây là điều gần nhất với “write-once-run-anywhere” trong thế giới infrastructure.
Serverless là proprietary nhất. Lambda trigger integrations, event source mappings, IAM execution roles, Layer system — tất cả đều deeply AWS-specific. Migrate một ứng dụng Lambda phức tạp sang Google Cloud Functions không phải là “lift-and-shift” — đó là viết lại. Bạn có đang định giá rủi ro này không?
VMs nằm ở giữa: AMIs là AWS-specific, nhưng OS và application stack hoàn toàn portable với effort hợp lý. Terraform + Packer giúp việc này dễ hơn nhiều.
Middle ground đang phát triển nhanh nhất là serverless containers: AWS Fargate, Google Cloud Run, Azure Container Apps. Bạn deploy OCI containers nhưng không cần quản lý cluster. Container portability kết hợp với serverless operational model. Nhưng lưu ý: API và configuration vẫn là cloud-specific.
Một xu hướng đáng theo dõi: WebAssembly (WASM) đang nổi lên như một fourth option với stronger portability và sandboxing promises — đặc biệt ở edge computing với Cloudflare Workers và WasmEdge.
Bảo Mật: Isolation, Attack Surface, và Compliance
VMs cung cấp isolation mạnh nhất — hardware-level hypervisor boundary. Đây là lý do tại sao các workload compliance-heavy (PCI-DSS, HIPAA, FedRAMP) vẫn ưa chuộng VMs. Một VM compromise không tự động dẫn đến compromise của VM khác trên cùng host.
Containers chia sẻ host kernel — một kernel exploit có thể theoretically escape container boundary. Log4Shell đã phơi bày rõ ràng supply chain risks trong deep dependency chains của container images. Bạn có biết tất cả những gì đang chạy trong base image của mình không?
Serverless giảm attack surface theo một nghĩa nào đó — không có persistent servers để patch. Nhưng nó introduces function permission sprawl và third-party event source trust issues. Ai có thể trigger Lambda function của bạn? Event source đó có được validate đúng cách không?
Shared responsibility model shifts theo abstraction level: càng nhiều abstraction thì càng nhiều security responsibility được giao cho cloud provider. Đây có thể là feature hoặc risk tùy thuộc vào compliance posture của tổ chức bạn.
https://blog.thnkandgrow.com/vi/serverless-container-hay-vm-danh-doi-that-su/feed/0LiteLLM vs CliProxyAPI: Hướng Dẫn Kết Hợp An Toàn 2026
https://blog.thnkandgrow.com/vi/litellm-vs-cliproxyapi-huong-dan-ket-hop-an-toan-2026/
Sat, 21 Mar 2026 10:13:56 +0000https://blog.thnkandgrow.com/?p=3455Kết hợp LiteLLM và CliProxyAPI nghe có vẻ tiện, nhưng làm sai là bạn đang mở cửa cho rủi ro bảo mật nghiêm trọng. Bài viết này hướng dẫn bạn mô hình tích hợp an toàn nhất — dùng LiteLLM làm lớp kiểm soát chính, cấu hình virtual key, Redis caching, fallback routing và audit logging đúng cách. Hiểu rõ điều này giúp bạn tối ưu chi phí mà không đánh đổi bảo mật trong môi trường production thực tế.
]]>Giới Thiệu: Tại Sao Quản Lý LLM API Trở Thành Vấn Đề Sống Còn Năm 2026
Nếu bạn đang xây dựng ứng dụng AI trong môi trường production năm 2026, việc gọi thẳng một LLM API duy nhất đã không còn là lựa chọn khả thi. Chi phí leo thang, rate limit bất ngờ, provider downtime, và yêu cầu tuân thủ dữ liệu ngày càng nghiêm ngặt — tất cả buộc các team phải nghĩ đến một lớp quản lý API thông minh hơn.
Trong bối cảnh đó, LiteLLM và CliProxyAPI nổi lên như hai công cụ được nhiều developer Việt Nam và châu Á nhắc đến cùng nhau. Nhưng đây là hai thứ hoàn toàn khác nhau về bản chất, mục đích, và mức độ rủi ro. Bài viết này sẽ phân tích kỹ từng công cụ, so sánh trực tiếp, và hướng dẫn cách kết hợp chúng một cách an toàn — nếu bạn thực sự cần làm vậy.
LiteLLM Là Gì? Tính Năng Cốt Lõi và Điểm Mạnh
LiteLLM là một open-source Python library và proxy server do BerriAI phát triển, được host tại github.com/BerriAI/litellm. Mục tiêu cốt lõi của nó là cung cấp một unified OpenAI-compatible interface để gọi hơn 100 LLM providers khác nhau — từ OpenAI, Anthropic Claude, Google Gemini, AWS Bedrock, Azure OpenAI, Groq, Mistral, cho đến các model local như Ollama.
Thay vì phải viết integration riêng cho từng provider, bạn chỉ cần một đoạn code duy nhất:
LiteLLM xử lý toàn bộ việc format request, parse response, và retry logic phía sau. Nhưng điều thực sự làm LiteLLM nổi bật là LiteLLM Proxy Server — một HTTP gateway có thể self-host, hoạt động như control plane cho toàn bộ LLM traffic của team bạn.
Các tính năng enterprise-grade của LiteLLM Proxy:
Load balancing: Phân phối traffic giữa nhiều models hoặc providers theo round-robin, least-latency, hoặc weighted routing
Virtual API keys: Tạo key ảo cho từng team/service mà không expose real provider keys
Cost tracking và budget limits: Theo dõi chi phí theo key, user, hoặc team; tự động block khi vượt budget
Rate limiting: Kiểm soát số requests per minute/day theo từng virtual key
Redis caching: Cache response để giảm redundant API calls
RBAC: Role-based access control cho môi trường enterprise
Observability integrations: Tích hợp với Langfuse, Helicone, Datadog, Prometheus để monitor toàn bộ traffic
Fallback routing: Tự động chuyển sang provider khác khi provider chính gặp lỗi
Về mặt cộng đồng, repository LiteLLM hiện có hơn 13.000 GitHub stars, hơn 10 triệu downloads mỗi tháng trên PyPI, và được cập nhật liên tục với nhiều release mỗi tuần. Đây là một trong những open-source LLM gateway trưởng thành và được tin dùng nhất hiện nay.
CliProxyAPI Là Gì? Hiểu Đúng Vai Trò Của Nó
CliProxyAPI là một CLI-based proxy tool được host tại github.com/router-for-me/CLIProxyAPI. Đây là một công cụ nhỏ gọn, định hướng CLI, cho phép developers route các LLM API calls thông qua một proxy endpoint tương thích OpenAI.
CliProxyAPI không phải là một framework lớn hay platform enterprise. Nó là một lightweight proxy layer, phổ biến trong cộng đồng developer Việt Nam và châu Á, thường được dùng trong các tình huống thực tế như:
Simplified authentication: Trừu tượng hóa việc quản lý API keys cho nhóm nhỏ
Cost sharing: Chia sẻ một API key hoặc quota trong team
OpenAI-compatible endpoint: Cung cấp endpoint chuẩn OpenAI để các tool khác dễ tích hợp
Quick local testing: Setup nhanh để test mà không cần cấu hình phức tạp
Lưu ý quan trọng: Cần phân biệt rõ giữa self-hosted proxy tools như CliProxyAPI (bạn tự chạy trên server của mình) và third-party proxy services (các dịch vụ trung gian do bên thứ ba vận hành). Khi sử dụng third-party proxy service bất kỳ — dù tên gọi là gì — bạn đang cho phép một bên thứ ba thấy toàn bộ API keys và nội dung prompt/response của mình. Đây là rủi ro bảo mật nghiêm trọng cần cân nhắc kỹ.
LiteLLM vs CliProxyAPI: So Sánh Trực Tiếp
Hai công cụ này không thực sự cạnh tranh nhau — chúng phục vụ các tầng khác nhau trong kiến trúc LLM API. Tuy nhiên, hiểu rõ sự khác biệt giúp bạn quyết định đúng:
Phạm vi và độ phức tạp
LiteLLM là một full-featured open-source gateway với hệ sinh thái hoàn chỉnh: dashboard UI, database backend (PostgreSQL), Helm charts cho Kubernetes, và hàng chục integrations. CliProxyAPI là một lightweight CLI-oriented proxy layer — đơn giản, nhanh setup, nhưng giới hạn về tính năng.
Kiểm soát dữ liệu và transparency
LiteLLM self-hosted cho bạn full data ownership — toàn bộ traffic, logs, và keys nằm trong infrastructure của bạn. CliProxyAPI khi self-hosted cũng tương tự, nhưng nếu bạn dùng một third-party instance của bất kỳ proxy tool nào, bạn đang mất đi sự kiểm soát đó.
Use cases phù hợp
LiteLLM: Team từ 3 người trở lên, production workloads, cần cost tracking, RBAC, và audit logs
CliProxyAPI: Individual developer, quick prototyping, hoặc làm backend endpoint trong một kiến trúc lớn hơn
Rủi Ro Bảo Mật Cần Biết Trước Khi Kết Hợp Hai Công Cụ
Trước khi đi vào hướng dẫn kết hợp, bạn cần nhìn thẳng vào các rủi ro thực tế:
1. API Key Exposure
Khi bạn route traffic qua bất kỳ proxy layer nào — dù là CliProxyAPI hay bất kỳ tool nào khác — real API keys của bạn có thể bị expose nếu proxy đó bị compromise. Đây là lý do tại sao virtual key system của LiteLLM quan trọng đến vậy.
2. Data Privacy
Mọi prompt và response đều đi qua intermediary layer. Nếu bạn xử lý dữ liệu nhạy cảm — thông tin khách hàng, dữ liệu y tế, tài chính — việc thêm một proxy layer mà bạn không kiểm soát hoàn toàn là vi phạm nghiêm trọng về compliance.
3. Rate Limit Abuse và Quota Leakage
Khi nhiều người dùng chung một proxy endpoint mà không có rate limiting đúng cách, một user có thể tiêu hết quota của cả team. LiteLLM giải quyết vấn đề này bằng per-key budget limits.
4. Unverified Proxy Endpoints
Cộng đồng developer thường chia sẻ proxy endpoints qua Telegram, Discord, hoặc forum. Không bao giờ dùng những endpoint này trong production. Bạn không biết ai đang đứng sau, logs gì được lưu, và keys của bạn có bị thu thập hay không.
Cách Kết Hợp LiteLLM và CliProxyAPI Một Cách An Toàn
Pattern an toàn nhất là: LiteLLM làm primary gateway, CliProxyAPI làm backend endpoint. LiteLLM kiểm soát toàn bộ authentication, logging, và rate limiting; CliProxyAPI chỉ là một trong nhiều provider endpoints mà LiteLLM route traffic đến.
Bước 1: Cấu hình CliProxyAPI như một custom provider trong LiteLLM
RBAC per virtual key: Mỗi team hoặc service nhận một virtual key riêng với quyền hạn và budget giới hạn
Redis caching: Bật semantic caching để tránh gọi lại những prompt giống nhau qua CliProxyAPI
Fallback routing: Cấu hình fallback để traffic tự động chuyển sang Anthropic hoặc Gemini nếu CliProxyAPI unavailable
Audit logs: Tích hợp Langfuse hoặc Helicone để có full visibility vào mọi request/response
Key rotation định kỳ: Rotate real provider keys mỗi 30-90 ngày và revoke virtual keys không còn sử dụng
Khi Nào Dùng LiteLLM Đơn Độc vs Kết Hợp Với CliProxyAPI
Dùng LiteLLM standalone khi bạn có direct access đến các LLM providers lớn (OpenAI, Anthropic, Google) và ưu tiên data control tuyệt đối. Đây là lựa chọn tốt nhất cho các team ở Việt Nam đã có billing account với providers.
Cân nhắc tích hợp CliProxyAPI khi bạn cần một lightweight proxy layer trong nội bộ team — ví dụ, một số thành viên không có trực tiếp API key nhưng cần access qua một endpoint kiểm soát được. Quan trọng: chỉ dùng instance mà bạn tự host và kiểm soát hoàn toàn.
Đánh giá các alternatives: Nếu vấn đề chính là access và cost, hãy xem xét OpenRouter (transparent pricing, nhiều models) hoặc One API (phổ biến trong cộng đồng developer Trung Quốc và châu Á, open-source). Cả hai đều có mức độ transparency cao hơn các proxy service ẩn danh.
Kết Luận: Bảo Mật Theo Lớp Là Nguyên Tắc Không Thể Bỏ Qua
LiteLLM và CliProxyAPI phục vụ hai vai trò bổ sung cho nhau trong kiến trúc LLM API — nhưng sự kết hợp này chỉ an toàn khi bạn thiết kế đúng từ đầu. LiteLLM là control plane: nơi mọi authentication, rate limiting, cost tracking, và observability được tập trung. CliProxyAPI — khi self-hosted — chỉ là một backend endpoint trong hệ thống đó, không phải điểm tin cậy độc lập.
Ba nguyên tắc bạn không được bỏ qua:
Không bao giờ tin tưởng mù quáng vào bất kỳ third-party proxy endpoint nào — dù được cộng đồng chia sẻ hay có vẻ đáng tin
Data ownership và auditability phải là yêu cầu không thể thương lượng trong bất kỳ LLM API strategy nào
Virtual keys, Redis caching, fallback routing, và audit logging không
là tùy chọn, mà là nền tảng bắt buộc của một LLM infrastructure production-grade
Những team xây dựng được ứng dụng LLM đáng tin cậy và hiệu quả về chi phí trong 2026 không phải là những người tìm shortcut nhanh nhất đến một API endpoint. Họ là những người xem mọi proxy layer như một bề mặt rủi ro tiềm năng, đo lường mọi thứ bằng observability, và duy trì quyền kiểm soát rõ ràng với từng byte dữ liệu chạy qua hạ tầng AI của mình.
Bắt đầu với self-hosted LiteLLM, bảo mật API key của bạn, bật audit log, và chỉ đưa CliProxyAPI — hoặc bất kỳ proxy layer nào — vào hệ thống khi bạn có thể xác minh chính xác dữ liệu đi đâu. Sự kỷ luật đó là thứ phân biệt một kiến trúc LLM production-grade với một sự cố bảo mật đang chờ xảy ra.
]]>DSPy + LiteLLM + ChatGPT: Xây Dựng Pipeline AI Thông Minh Hơn Năm 2026
https://blog.thnkandgrow.com/vi/dspy-litellm-chatgpt-pipeline-ai-thong-minh-2026/
Sat, 21 Mar 2026 00:41:33 +0000https://blog.thnkandgrow.com/?p=3448Hết thời viết prompt thủ công rồi vá víu khi model thay đổi. Bài này hướng dẫn bạn kết hợp DSPy và LiteLLM để xây pipeline LLM có thể tối ưu prompt tự động, đổi model tùy ý — từ ChatGPT đến Ollama chạy local — mà không cần sửa một dòng code nào. Đây là kiến trúc giúp bạn kiểm soát chi phí, tăng độ ổn định và scale thực sự trong môi trường production.
]]>Mở Đầu: Khi Prompt Engineering Trở Thành Gánh Nặng
Bạn đã bao giờ dành cả buổi chiều để tinh chỉnh một prompt, chỉ để nhận ra rằng khi đổi model hoặc thêm một bước xử lý mới, toàn bộ logic lại sụp đổ? Đó là thực tế mà hầu hết các kỹ sư AI đang đối mặt vào năm 2026. Prompt engineering thủ công vừa tốn thời gian, vừa dễ vỡ, vừa cực kỳ khó bảo trì khi hệ thống scale lên.
May mắn thay, một kiến trúc ba lớp đang nổi lên như một giải pháp thực tiễn và mạnh mẽ: DSPy để tối ưu hóa pipeline thông minh, LiteLLM (hoặc các CLI Proxy API tương tự) để kiểm soát chi phí và linh hoạt chuyển đổi model, và ChatGPT-compatible APIs làm chuẩn giao tiếp thống nhất. Kết hợp lại, ba công nghệ này tạo ra một kiến trúc mà bạn có thể viết một lần, chạy ở bất kỳ đâu — từ GPT-4o của OpenAI đến mô hình Llama chạy local — mà không cần thay đổi một dòng code nào.
Bài viết này sẽ đi sâu vào từng thành phần, cách kết nối chúng lại với nhau, và những best practices để xây dựng LLM pipeline chuẩn production trong năm 2026.
DSPy Là Gì Và Tại Sao Nó Thay Đổi Cuộc Chơi
DSPy (Declarative Self-improving Python) được phát triển bởi Omar Khattab và nhóm Stanford NLP, với một triết lý cốt lõi rất khác biệt: thay vì viết prompt, bạn định nghĩa hành vi.
Trong DSPy, bạn khai báo Signature — tức là input và output mà bạn mong muốn — và framework sẽ tự động compile, tối ưu hóa prompt phù hợp. Không còn việc ngồi căn chỉnh từng từ trong prompt template nữa.
Các Abstraction Chính Trong DSPy
Signatures: Định nghĩa “hợp đồng” giữa input và output. Ví dụ: question -> answer hay context, question -> reasoning, answer.
Modules: Các khối xây dựng pipeline như dspy.ChainOfThought (suy luận từng bước) và dspy.ReAct (agent sử dụng tool). Chúng hoạt động giống như các layer trong neural network — có thể kết hợp và tái sử dụng.
Teleprompters / Optimizers: Đây là phần ma thuật. Các optimizer như BootstrapFewShot và MIPRO v2 tự động tìm kiếm các few-shot examples và cấu hình prompt tối ưu dựa trên metric bạn định nghĩa.
Sự thay đổi tư duy ở đây rất quan trọng: thay vì prompt engineering, bạn đang làm program-based LLM development. Pipeline của bạn là một chương trình có cấu trúc, có thể test, debug, và optimize một cách hệ thống — không phải một đống string template dễ vỡ.
CLI Proxy API Là Gì Và Tại Sao Bạn Cần Nó
CLI Proxy API là một lớp middleware đứng giữa code của bạn và các LLM provider. Nó expose một giao diện thống nhất — thường là OpenAI-compatible — để bạn có thể gọi bất kỳ model nào mà không cần thay đổi code ứng dụng.
Các Công Cụ Nổi Bật Trong Danh Mục Này
LiteLLM: Proxy phổ biến nhất, hỗ trợ 100+ provider. Có thể khởi động bằng một lệnh CLI duy nhất và cung cấp đầy đủ tính năng production như caching, logging, fallback, và load balancing.
Ollama: Giải pháp lý tưởng để chạy model local (Llama, Mistral, Qwen…) với OpenAI-compatible endpoint.
vLLM: Inference server hiệu năng cao cho GPU, phù hợp với enterprise deployment.
OpenRouter: Cloud-based router cho phép truy cập nhiều model từ nhiều provider qua một API key duy nhất.
LocalAI: Tương tự Ollama nhưng hỗ trợ nhiều backend hơn, phù hợp với môi trường on-premise.
Lợi Ích Cốt Lõi
Lý do bạn cần một proxy layer không chỉ là tiện lợi — đó là chiến lược:
Loại bỏ vendor lock-in: Hôm nay dùng GPT-4o, ngày mai muốn thử Claude hay Gemini? Chỉ cần đổi config proxy, không cần sửa code.
Kiểm soát chi phí: Route các task đơn giản sang model rẻ hơn, task phức tạp mới dùng model đắt tiền.
Private inference: Dữ liệu nhạy cảm? Chạy Ollama local, không một byte nào rời khỏi máy chủ của bạn.
Request routing thông minh: LiteLLM cho phép thiết lập fallback tự động — nếu GPT-4o timeout, tự động chuyển sang model backup.
ChatGPT Fits Into Architecture Như Thế Nào
OpenAI không chỉ là một LLM provider — họ đã định nghĩa chuẩn giao tiếp mà cả ngành đang dùng. Endpoint /v1/chat/completions với format JSON của OpenAI đã trở thành lingua franca của thế giới LLM, và đó là lý do tại sao tất cả các proxy tool đều emulate nó.
Dòng Model Hiện Tại (2026)
GPT-4o: Model đa năng mạnh nhất, hỗ trợ multimodal, phù hợp với reasoning phức tạp.
GPT-4o-mini: Rẻ hơn đáng kể, chất lượng tốt cho các task classification, extraction, summarization.
o1/o3 reasoning models: Dành cho các bài toán cần extended thinking — toán học, lập luận nhiều bước, code phức tạp. Chi phí cao hơn nhưng độ chính xác vượt trội.
DSPy hỗ trợ tất cả các endpoint OpenAI-compatible thông qua wrapper dspy.LM. Pattern chuẩn hiện nay là:
import dspy
lm = dspy.LM(
"openai/gpt-4o",
base_url="http://localhost:4000",
api_key="anything" # LiteLLM xử lý auth nội bộ
)
dspy.configure(lm=lm)
Bước 4: Xây Dựng Pipeline DSPy Đơn Giản
class QASignature(dspy.Signature):
"""Trả lời câu hỏi dựa trên ngữ cảnh được cung cấp."""
context: str = dspy.InputField()
question: str = dspy.InputField()
answer: str = dspy.OutputField()
class SmartQA(dspy.Module):
def __init__(self):
self.cot = dspy.ChainOfThought(QASignature)
def forward(self, context, question):
return self.cot(context=context, question=question)
qa = SmartQA()
result = qa(
context="DSPy là framework tối ưu hóa LLM pipeline tự động.",
question="DSPy làm gì?"
)
print(result.answer)
Chỉ vậy thôi. Pipeline của bạn đang chạy qua LiteLLM proxy, và bạn có thể switch sang bất kỳ model nào chỉ bằng cách thay đổi config.
Các Use Case Thực Tế Của Stack Này
1. Pipeline Tối Ưu Chi Phí
Đây là use case phổ biến nhất trong môi trường production. Với LiteLLM, bạn có thể thiết lập routing rules: các task phức tạp như phân tích pháp lý hay reasoning nhiều bước được route sang GPT-4o, trong khi classification đơn giản hay trích xuất entity được gửi đến GPT-4o-mini. Kết quả thực tế: tiết kiệm 60–80% chi phí API mà không giảm chất lượng đáng kể.
2. Private/Enterprise Inference
Nếu bạn làm việc với dữ liệu y tế, tài chính, hay pháp lý — dữ liệu không thể rời khỏi infrastructure của bạn — chỉ cần thay đổi config LiteLLM để point sang Ollama chạy local:
Không cần thay đổi một dòng DSPy code nào. Đây chính là sức mạnh của kiến trúc này.
3. Multi-Model Experimentation
Dùng DSPy’s optimizer để benchmark cùng một pipeline logic trên nhiều model khác nhau qua proxy. Bạn có thể so sánh GPT-4o vs Claude vs Llama trên cùng một metric đánh giá, từ đó chọn model tốt nhất cho từng task cụ thể.
Best Practices Và Những Lỗi Cần Tránh
Nên Làm
Luôn dùng dspy.configure(lm=...) làm phương thức setup model chính. Cách này tạo ra code sạch, dễ bảo trì, và dễ swap model khi cần.
Tận dụng LiteLLM caching với Redis để giảm chi phí cho các request lặp lại — đặc biệt hữu ích trong quá trình development và testing.
Bật logging PostgreSQL trong LiteLLM để có visibility đầy đủ về chi phí, latency, và error rate của từng model.
Test proxy connectivity trước khi chạy DSPy optimization loops. Một optimization run có thể tốn hàng trăm API calls — đừng để lỗi kết nối làm hỏng cả quá trình.
Không Nên Làm
Đừng over-optimize quá sớm. Chỉ chạy DSPy teleprompters (như MIPRO v2) sau khi pipeline logic của bạn đã ổn định. Optimize một pipeline chưa hoàn thiện là lãng phí tài nguyên.
Đừng hardcode API key trong code DSPy. Để LiteLLM proxy xử lý authentication — code của bạn chỉ cần biết địa chỉ proxy.
Đừng bỏ qua evaluation. DSPy cung cấp dspy.Evaluate — hãy định nghĩa metric rõ ràng trước khi chạy optimizer, nếu không kết quả optimize sẽ vô nghĩa.
Toàn Cảnh Hệ Sinh Thái: Con Người, Công Cụ Và Tương Lai
Để hiểu đầy đủ về stack này, cần biết những người đứng sau nó:
Omar Khattab (Stanford → Databricks): Cha đẻ của DSPy, hiện đang phát triển framework dưới sự hỗ trợ của Databricks với nguồn lực lớn hơn nhiều.
Stanford NLP Group: Nơi DSPy được sinh ra, tiếp tục đóng góp research về automatic prompt optimization.
Ishaan Jaffer: Co-creator của LiteLLM, đang xây dựng enterprise tier với các tính năng như SSO, audit logging, và role-based access control.
DSPy 2.5+ và Những Gì Đang Đến
DSPy 2.5+ đã mang lại nhiều cải tiến đáng kể: multi-LM support trong một pipeline duy nhất, async execution, MIPRO v2 với hiệu quả tối ưu hóa tốt hơn, và bridges với LangChain/LlamaIndex để tích hợp vào ecosystem rộng hơn.
Nhìn về phía trước, ba xu hướng đáng chú ý:
Structured Outputs: Native JSON schema enforcement từ OpenAI kết hợp với DSPy Signatures tạo ra pipeline cực kỳ reliable.
Reasoning Models (o3): DSPy’s optimizer sẽ học cách tận dụng extended thinking của o3 cho các task phức tạp nhất.
Enterprise Adoption: Ngày càng nhiều tổ chức lớn đang adopt stack này như một standard architecture cho LLM applications.
Kết Luận: Bắt Đầu Nhỏ, Scale Lớn
Kiến trúc ba lớp — DSPy cho pipeline logic thông minh, CLI Proxy API cho sự linh hoạt và kiểm soát chi phí, ChatGPT-compatible APIs làm chuẩn giao tiếp thống nhất — không phải là một xu hướng nhất thời. Đây là một trong những kiến trúc thực tiễn nhất để xây dựng LLM systems chu